安卓 - 2026腾讯游戏安全竞赛(初赛)题解
1. 逆向分析过程
1.1 工具与环境
1.2 APK 基本结构分析
使用 jadx 对 APK 进行反编译,结合 unzip 提取资源,确认以下基本信息:
游戏引擎:Godot 4.5.1(标准 Godot Android 模板,主库so, 可从xml清单文件提取版本号)
游戏逻辑资源:打包于 assets/assets.sparsepck,采用自定义 AES-256 加密
原生扩展库:so,包含 flag 核心计算逻辑,以 GDExtension 形式注册
PCK 目录本身也经过加密(PACK_DIR_ENCRYPTED 标志位置位)
APK 内关键文件列表:
assets/assets.sparsepck — 加密 PCK(包含所有 .gdc 脚本和场景)
lib/arm64-v8a/libgodot_android.so — Godot 引擎主库
lib/arm64-v8a/libsec2026.so — 赛题自定义扩展(flag 生成核心)
1.3 PCK 资源解密分析
1.3.1 定位 AES 密钥
对照godot源代码, 使用字符串大法!!!
通过 IDA 静态分析 libgodot_android.so,在 FileAccessEncrypted::open_and_parse 的交叉引用路径上,定位到 script_encryption_key(偏移 0x400EDF0),读出 32 字节密钥:
AES-256 Key: ce4df8753b59a5a39ade58ac07ef947a3da39f2af75e3284d51217c04d49a061
同时逆向分析发现,Godot 此版本对 CFB 模式进行了魔改——标准 CFB128 的基础上,每个字节额外 XOR 了其在块内的偏移量 (i % 16),并且使用加密 key schedule(非解密 key schedule):
# 魔改 CFB 解密伪代码
for i in range(len(data)):
offset = i % 16
if offset == 0: encrypted_iv = AES_ECB_Encrypt(key, iv_buf)
result[i] = encrypted_iv[offset] ^ data[i] ^ offset
iv_buf[offset] = data[i] ^ offset
PCK 文件头中的加密标志(flags = 0x05)指示目录表和文件数据均被加密,加密格式头部已去掉标准 GDEF magic,直接以 [16 字节 MD5][8 字节明文长度][16 字节 IV][密文] 布局存储。
1.3.2 批量解密脚本
#!/usr/bin/env python3
# 解密 sec2026 APK 里的 godot pck 资源
# assets.sparsepck 是目录,实际文件散落在 assets/ 各子目录里
# 加密用的是魔改 CFB,标准 pycryptodome 的 CFB 模式解不开,得手动实现
#
# 用法: python3 extract_sparse.py <apk解压后的assets目录> [-o 输出目录]
import struct
import hashlib
import os
import sys
from Crypto.Cipher import AES
# 从 libgodot_android.so 偏移 0x400EDF0 读出来的密钥
KEY = bytes.fromhex("ce4df8753b59a5a39ade58ac07ef947a3da39f2af75e3284d51217c04d49a061")
GDPC_MAGIC = 0x43504447 # "GDPC"
# Godot 魔改版 CFB
# 在 IDA 里看 sub_197DE18,核心差异有两点:
# 1. 每个字节结果额外 XOR 了 (i % 16)
# 2. IV 反馈时存的是 data[i] ^ offset,不是原始密文
# 标准 pycryptodome CFB128 完全解不开,md5 对不上,折腾了一会才发现这里被改了
def godot_cfb_decrypt(key, iv, data):
ecb = AES.new(key, AES.MODE_ECB)
iv_buf = bytearray(iv)
out = bytearray(len(data))
for i in range(len(data)):
off = i % 16
if off == 0:
keystream = ecb.encrypt(bytes(iv_buf))
out[i] = keystream[off] ^ data[i] ^ off
iv_buf[off] = data[i] ^ off
return bytes(out)
# FileAccessEncrypted envelope 格式(magic "GDEF" 被去掉了,直接从 MD5 开始):
# [16] MD5 of plaintext
# [8] plaintext length (uint64 LE)
# [16] IV
# [...] ciphertext (padded to 16 bytes)
def decrypt_file(raw, fname=""):
if len(raw) < 40:
return None
stored_md5 = raw[:16]
pt_len = struct.unpack_from("<Q", raw, 16)[0]
iv = raw[24:40]
ct = raw[40:]
# ciphertext 按 16 字节对齐
padded = (pt_len + 15) & ~15
if len(ct) < padded:
print(f" [!] {fname}: ct too short ({len(ct)} < {padded})")
return None
ct = ct[:padded]
pt = godot_cfb_decrypt(KEY, iv, ct)[:pt_len]
if hashlib.md5(pt).digest() != stored_md5:
# 正常不应该走到这里,如果走到说明密钥或算法有问题
print(f" [!] {fname}: md5 mismatch, stored={stored_md5.hex()}")
return pt # 先把数据返回去看看
return pt
def parse_dir(sparsepck_path):
with open(sparsepck_path, "rb") as f:
magic = struct.unpack("<I", f.read(4))[0]
if magic != GDPC_MAGIC:
print(f"bad magic: {magic:#x}")
return []
pack_ver = struct.unpack("<I", f.read(4))[0]
major, minor, patch = struct.unpack("<III", f.read(12))
flags = struct.unpack("<I", f.read(4))[0]
_file_base = struct.unpack("<Q", f.read(8))[0]
enc_dir = bool(flags & 1)
enc_files = bool(flags & 4)
print(f"Godot {major}.{minor}.{patch}, pack_ver={pack_ver}, flags={flags:#x}")
print(f" enc_dir={enc_dir} enc_files={enc_files}")
# v3 多了个 dir_offset 字段
if pack_ver == 3:
dir_offset = struct.unpack("<Q", f.read(8))[0]
f.seek(dir_offset)
elif pack_ver <= 2:
f.read(64)
file_count = struct.unpack("<I", f.read(4))[0]
print(f" {file_count} files in directory")
if enc_dir:
raw_dir = f.read()
dir_data = decrypt_file(raw_dir, fname="[directory]")
if dir_data is None:
print("directory decrypt failed")
return []
else:
dir_data = f.read()
entries = []
pos = 0
for _ in range(file_count):
if pos + 4 > len(dir_data):
break
path_len = struct.unpack_from("<I", dir_data, pos)[0]; pos += 4
path = dir_data[pos:pos+path_len].decode("utf-8", errors="replace").rstrip("\x00"); pos += path_len
offset, size = struct.unpack_from("<QQ", dir_data, pos); pos += 16
md5 = dir_data[pos:pos+16].hex(); pos += 16
file_flags = struct.unpack_from("<I", dir_data, pos)[0]; pos += 4
entries.append({
"path": path, "offset": offset, "size": size,
"md5": md5, "enc": bool(file_flags & 1),
})
return entries
def main():
if len(sys.argv) < 2:
print(f"usage: {sys.argv[0]} <assets_dir> [-o outdir]")
sys.exit(1)
assets_dir = sys.argv[1]
out_dir = "out"
if "-o" in sys.argv:
out_dir = sys.argv[sys.argv.index("-o") + 1]
sparsepck = os.path.join(assets_dir, "assets.sparsepck")
if not os.path.exists(sparsepck):
print(f"找不到 {sparsepck}")
sys.exit(1)
entries = parse_dir(sparsepck)
if not entries:
sys.exit(1)
os.makedirs(out_dir, exist_ok=True)
ok = err = skip = 0
for e in entries:
rel = e["path"].replace("res://", "")
# 过滤掉路径穿越之类的东西
parts = [p for p in rel.split("/") if p and p not in ("..", ".")]
rel = "/".join(parts) if parts else "_unknown"
src = os.path.join(assets_dir, rel)
dst = os.path.join(out_dir, rel)
if not os.path.isfile(src):
skip += 1
continue
os.makedirs(os.path.dirname(dst), exist_ok=True)
raw = open(src, "rb").read()
if e["enc"]:
pt = decrypt_file(raw, fname=rel)
if pt is None:
print(f" ERR {rel}")
err += 1
continue
open(dst, "wb").write(pt)
print(f" OK {rel} ({len(pt)} bytes)")
ok += 1
else:
open(dst, "wb").write(raw)
ok += 1
print(f"\ndone: {ok} ok, {err} err, {skip} skip -> {out_dir}/")
if __name__ == "__main__":
main()编写 python 实现完整的 PCK 稀疏格式解析与解密,成功解密出所有 .gdc 脚本文件,包括关键的 trigger.gd 和 token.gd:
第一阶段:解析 PCK 头部 读取 assets.sparsepck 文件,验证 GDPC magic(0x43504447),提取版本号、flags 字段。flags 中的位标志决定后续处理方式:bit0 = 目录加密,bit1 = 相对偏移,bit2 = 文件加密。
第二阶段:解密目录表 由于 flags 中 PACK_DIR_ENCRYPTED 置位,目录表本身也是密文。工具将目录区数据整体作为一个加密 envelope 处理,调用 decrypt_envelope() 解密后,再按 Godot PCK 格式逐条解析文件路径、偏移、大小、MD5、per-file flags。
第三阶段:decrypt_envelope 核心解密 这是最关键的部分。envelope 格式为:[16字节 MD5][8字节明文长度][16字节 IV][密文...]
工具会依次尝试四种模式(Godot-CFB / CFB128 / CBC / ECB),用 MD5 比对来判断哪种模式解密成功。赛题实际使用的是 Godot 魔改 CFB:在标准 CFB128 的基础上,每个字节额外 XOR 了块内偏移 i % 16,IV 回填时也填入 data[i] ^ offset 而非原始密文字节。
第四阶段:逐文件解密与输出 对目录中每个 PACK_FILE_ENCRYPTED 的文件,从 assets/ 目录找到对应源文件,同样走 decrypt_envelope() 解密,解密完成后用目录中存储的 MD5 做完整性校验,通过则写入输出目录。未加密的文件直接原样复制。
整个流程的关键前提是拿到正确的 32 字节 AES-256 密钥(从 libgodot_android.so 静态分析获得),没有密钥则 MD5 校验永远失败,四种模式都会返回乱码。
1.4 Flag 触发机制分析
通过运行 APK 并操控小车,观察到以下触发行为(绿色方块位于场景中房顶附近高处,需驾车到达触发区域):
1.4.1 Part0(黄色示例方块)
触发条件:小车到达黄色方块区域,屏幕右上角显示固定示例 flag,不计分。
示例输出:flag{sec2026_PART0_example}
1.4.2 Part1(绿色方块)
触发条件:小车到达绿色方块区域即触发。
触发逻辑来自解密后的 trigger.gd(路径 /root/TownScene/Trigger2):
elif str(get_path()) == "/root/TownScene/Trigger2":
var label = get_node("/root/TownScene/Label2")
var label1 = get_node("/root/TownScene/Label")
var flag1 = obj.Process(xor_enc(str(label1.text).substr(7)))
label.text = "flag{" + FLAG_PREFIX + flag1 + "} "1.5 libsec2026.so 逆向分析
1.5.1 自解密 Loader(start 函数)
.init_array[0] 挂了一个叫 start 的函数(IDA 偏移 0x56D50 附近),一开始没太在意,以为是普通的全局构造器,结果看伪代码发现根本不是——它全程用 raw syscall,完全绕开 libc,做的事情也很有意思:
先 openat 读 /proc/self/auxv 拿辅助向量,然后调 sub_69984 把 .data 段里一块加密数据解出来,接着 memfd_create 创建一个匿名 fd,把解密结果写进去,再 mmap(PROT_READ|PROT_EXEC) 映射成可执行内存,最后 BR X14 直接跳进去跑。
说白了这个 so 本身就是个壳,真正的代码是运行时解密出来的,磁盘上看到的全是密文。不过因为 dump 是在 .init_array 跑完之后做的,内存里已经是解密后的状态,所以 dump 出来的文件可以直接在 IDA 里分析。
1.5.2 硬编码密钥解密(sub_4CC48)
同在 .init_array 阶段跑的还有 sub_4CC48,它对 0xED5D2 处的 33 字节做了一轮 XOR 解密,密钥是硬编码的 64-bit 值 0x97A36EF7A74F5E4E(小端拆开循环用):
key = [0x4E, 0x5E, 0x4F, 0xA7, 0xF7, 0x6E, 0xA3, 0x97]
for i in range(33):
plaintext[i] = ciphertext[i] ^ key[i % 8]dump 下来看内存,解出来的结果是:Th1s ls n0t a rea1 key!!@sec2026
第一眼看到这串东西确实有点迷惑,"This is not a real key" 感觉像是在嘲讽分析者。但实际跑起来这 32 字节就是真正的 ChaCha20 Key,没有任何其他处理,直接拿来用的。紧接在后面 0xED5F3 处还有个 "012345678901" 作为 12 字节 Nonce。
因为就算拿到这个 key,配标准 ChaCha20 还是算不出正确的 flag,真正的"假"在接下来的加密算法的那 16 字节常量里。
1.5.3 GDExtension 注册(extension_init)
extension_init(偏移 0x56D50)通过混淆跳转进入注册逻辑:
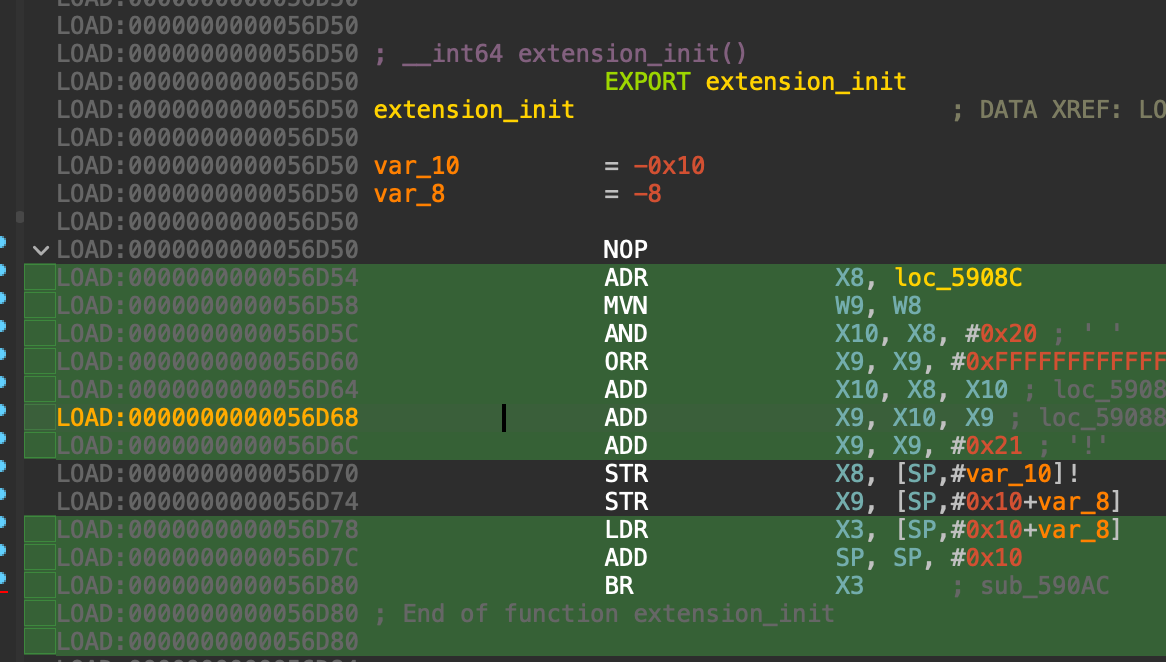
sub_4DF6C 完成 GameExtension 类的注册,将 Process 方法绑定到 ProcessHandler(偏移 0x4E198)
等价于:ClassDB::bind_method(D_METHOD("Process","Input"), &GameExtension::Process)
1.5.4 Do_ChaCha20_HexEncode 函数(偏移 0x4E548)
ProcessHandler 最终走到 Do_ChaCha20_HexEncode(0x4E548),逻辑也是比较直接的,把 IDA 里的跳表混淆捋清楚之后其实没什么东西:
ctx = ChaCha20_AllocContext();
ChaCha20_Init(ctx,
"Th1s ls n0t a rea1 key!!@sec2026", // 32字节 key,0xED5D2
"012345678901", // 12字节 nonce,0xED5F3
0); // counter 从 0 开始
ChaCha20_Update(ctx, input, output, in_len);
// 输出转大写 hex,格式就是 %02X 挨个拼
for i in range(in_len):
hex_string += format("%02X", output[i])
return hex_string块函数本身是标准 RFC 8439 的 10 轮 double round,但 ChaCha20_Init 在 0x5B848 加载的不是标准的 "expand 32-byte k",而是被改成了 "fxpaod 31-byse k"(每个 32-bit 字都差 ±1)。这 16 字节通过 memcpy_chk 直接写入 state[0..3],其余初始化流程(8 个 key word + counter + 3 个 nonce word)完全标准。这是本题唯一的密码学魔改点,但足以让所有直接套用 RFC 8439 的实现失效。
关键地址汇总:
2. 算法逻辑说明
整个 flag 生成就三步,GDScript 负责前处理,Native 层做加密:
Token(8位随机hex)
│
▼ xor_enc() ← trigger.gd
8字节 XOR 链:result[i] ^= result[i+1](i=0..6),result[7] ^= result[0]
│
▼ ChaCha20_Update() ← libsec2026.so
逐字节 XOR keystream,只用前8字节
│
▼ %02X 大写 hex 编码
16字符 hex 后缀
│
▼
flag{sec2026_PART1_<suffix>}2.1 Token 生成(token.gd)
解密 gdc 后看到 token.gd 很简单,_ready() 里随机生成 8 位 hex 字符串显示在左上角,每次开局都会换:
const TOKEN_LEN = 8
const CHARS = "0123456789abcdef"
func generate_token(len: int) -> String:
var s = ""
for i in len:
s += CHARS[rng.randi_range(0, CHARS.length() - 1)]
return strigger.gd 里取 token 的方式是 str(label1.text).substr(7),直接把 "Token: " 这个前缀(7个字符)截掉。
2.2 xor_enc(trigger.gd)
这个函数对 token 的 UTF-8 字节做了一轮前向 XOR 链,最后尾字节再跟首字节 XOR 一次:
func xor_enc(plain: String) -> PackedByteArray:
var result = plain.to_utf8_buffer().slice(0, 8)
for i in range(7):
result[i] = result[i] ^ result[i + 1]
result[7] = result[7] ^ result[0]
return result2.3 ChaCha20 加密(libsec2026.so)
key 和 nonce 都是硬编码的,前面分析 sub_4CC48 时已经拿到了:
输入只有 8 字节,所以实际只用了 keystream 第一个 block 的前 8 字节,之后大写 hex 编码拼出 flag:
keystream = ChaCha20_Block(key, nonce, counter=0)
cipher[i] = xor_buf[i] ^ keystream[i] # i = 0..7验证向量:
a1b2c3d4 → flag{sec2026_PART1_2A4C031823617318}
cf14eaad → flag{sec2026_PART1_7F4856187736261D}
deadbeef → flag{sec2026_PART1_7B1B564F7436201B}3. 可逆性分析
三步全都可逆,没有哈希或单向操作:
3.1 xor_enc 逆向
正向跑完之后各字节的关系是:
r[0] = a[0] ^ a[1]
r[1] = a[1] ^ a[2]
r[2] = a[2] ^ a[3]
r[3] = a[3] ^ a[4]
r[4] = a[4] ^ a[5]
r[5] = a[5] ^ a[6]
r[6] = a[6] ^ a[7]
r[7] = a[7] ^ r[0] ← 注意这里的 r[0] 是已经被 XOR 过的值,不是原始 a[0]
展开就是 r[7] = a[7] ^ a[0] ^ a[1]所以逆向有一个顺序陷阱:必须先处理 r[7],再从后往前拆前面的 XOR 链。原因是尾字节的还原依赖当前的 r[0](也就是 a[0]^a[1]),一旦先把 r[0] 还原成 a[0],r[7] 里的 a[0]^a[1] 就再也凑不出来了。正确顺序:
def xor_enc_reverse(r):
# Step 1: 先还原 r[7]。此时 r[0] 仍是 a[0]^a[1],
# r[7] ^ r[0] = (a[7]^a[0]^a[1]) ^ (a[0]^a[1]) = a[7]
r[7] ^= r[0]
# Step 2: 从 i=6 往前,每一步用已经还原好的 r[i+1] 去拆 r[i]
# r[i] = a[i]^a[i+1],XOR 上 a[i+1] 即得 a[i]
for i in range(6, -1, -1):
r[i] ^= r[i + 1]
return r正确性证明(数学归纳):
基础: Step 1 之后
r[7] = a[7],成立。归纳: 假设
r[i+1] = a[i+1]已经还原好。由于r[i]在 Step 1 和之前的循环迭代中都没被碰过,它仍等于正向结果a[i]^a[i+1]。执行r[i] ^= r[i+1]后:r[i] = (a[i] ^ a[i+1]) ^ a[i+1] = a[i]从
i=6递减到i=0,所有r[i]依次还原为a[i],完成逆向。