Java21 - 虚拟线程
就了解一下
对于刚接触虚拟线程的人来说,其普遍被认为是一种“轻量级线程,可以提高开发效率?” 。他的强大的点就是,在发生堵塞的时候可以自动暂停和恢复,从底层系统中解放这个线程,让这个线程可以去干别的事情。
虚拟线程并非1:1的和一个专门的OS级别线程对应,观看线程池任务,可以看出当虚拟线程进入堵塞的时候,Future会放弃占用OS线程,将该OS线程放走(让他去干别的事情),而虚拟线程自己只保留在内存中,直到恢复运行位置(堵塞、等待的代码结束了)。但是并不保证虚拟线程仍旧运行在之前的OS线程中,也可能是一个新建的、别人用过的、自己之前用的...在JEP 444的描述中,OS线程被称为承载线程,而虚拟线程被叫做挂载线程。
类似的概念
说到这个,我就想起来了kotlin的协程,这两个东西有什么区别呢?
协程的优势在于其非堵塞的控制流,但开发者想要使用意味着必须编写异步代码并使用async\await ,这往往会增加代码复杂性(其实就是你懒得学罢了)。而虚拟线程对于开发者完全透明,开发者无需额外学习什么异步编程模型,无需顾忌什么同步代码和异步代码混用的无聊问题。
高情商:虚拟线程主要是为了解决传统线程的高开销的问题。
Go的协程和kotlin的区别?为什么Go的要更快?
在大多数测试中,go的协程都比kotlin的要快,在高并发场景下,golang以其低内存占用的协程遥遥领先,这主要归功于golang高效的调度机制(GMP模型)而kotlin的是一种协作式调度。
在很多场景下,即使是rust来了,rust的大部分web框架高并发情况下也只能和golang几乎在同一个水平,而且内存占用会比golang略高?而某些语言开发者自欺欺人,认为其垃圾语言的协程的实现要比golang更高效?实际上只不过就是一个幌子,在我的一个历史测试中(真实业务代码,将一个需要对数据库读写,使用了两个不同的语言,其中一个是golang),这个垃圾语言只能达到63%的golang并发水平之后疯狂超时,所有的请求都被抛弃,直到并发请求数量降下去了!
为什么要做虚拟线程?
服务端程序的并发受到利特尔定律的限制,线程的启动有开销,即使你使用了线程池虽然可以解决一定开销,但是OS系统中实际能运行的线程数量也是有限的,即真正同时在运行的线程,这个时候你的系统的网络、CPU都没有耗尽,这点就桎梏了并发。
例如,假设平均延迟为 50 毫秒的应用程序通过并发处理 10 个请求实现了每秒 200 个请求的吞吐量。为了使该应用程序扩展到每秒 2000 个请求的吞吐量,它将需要并发处理 100 个请求。如果每个请求在请求持续时间内都在一个线程中处理,那么为了使应用程序跟上,线程数必须随着吞吐量的增长而增长。
线程数量的增长就会大量消耗资源,按照Java宗教圣经来说就是“内存不值钱”
使用异步方式提高可扩展性
一些希望充分利用硬件的开发者(协程异教徒)放弃了每个请求独占一个线程,转而采用线程共享。请求处理代码不是从头到尾在一个线程上处理请求,而是在等待 I/O 操作完成时将其线程返回到池中,以便该线程可以处理其他请求。这种细粒度的线程共享(代码仅在执行计算时而不是等待 I/O 时才保留线程)允许大量并发操作而不消耗大量线程。虽然它消除了操作系统线程稀缺造成的吞吐量限制,但代价很高:它需要所谓的异步编程风格,采用一组单独的 I/O 方法,这些方法不等待 I/O 操作完成,而是稍后将其完成信号发送给回调。如果没有专用线程,开发人员必须将请求处理逻辑分解为小阶段,通常以 lambda 表达式的形式编写,然后使用 API 将它们组合成顺序管道(例如,参见CompletableFuture或所谓的“反应式”框架)。因此,他们放弃了该语言的基本顺序组合运算符,例如循环和try/catch块。
用kotlin解决上述的问题,说白了就是语法不够先进,过于质朴罢了~
在异步样式中,请求的每个阶段可能在不同的线程上执行,并且每个线程以交错方式运行属于不同请求的阶段。这对于理解程序行为具有深远的影响:堆栈跟踪不提供可用的上下文,调试器无法逐步执行请求处理逻辑,并且分析器无法将操作的成本与其调用者关联起来。当使用 Java 的流API在短管道中处理数据时,编写 lambda 表达式是可管理的,但是当应用程序中的所有请求处理代码都必须以这种方式编写时,就会出现问题。这种编程风格与 Java 平台不一致,因为应用程序的并发单元(异步管道)不再是平台的并发单元。
闲得无聊,说这么多,实际上就是为了兼容老的代码,让大家伙都偷偷懒,但是呢?你这么帮助开发者偷懒,别的语言都在嘲笑你哦!因为你连
await、async都不放出来,让开发者自己去控制同步代码和异步代码的融合,把所有的Java标准库的会堵塞的代码都实现一个附加了suspend/async关键字的版本,你也轻松,还能让一些人闭嘴,阿J啊,你错付了~
和开头说的一样虚拟线程也是java.lang.Thread 但是和 OS 线程没什么特定关系。OS线程也是java.lang.Thread,是以传统方式实现的,这个Thread实例是 OS 线程的一个薄包装器。
虚拟线程的使用
直接创建原地运行一个虚拟线程
Thread vt = Thread.startVirtualThread(() -> {
System.out.ptintln(114514); // 万年狗屎sout
Thread.sleep(10);
});或者手动调用start()来运行
Thread vt = Thread.ofVirtual().unstarted(() -> {
System.out.ptintln(1919); // 万年狗屎sout
Thread.sleep(10);
System.out.println(810);
});下方代码直接创建了10000个虚拟线程
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits和Java虚拟线程滥交
以下是一个Java JEP425服务器应用程序的官方示例,该应用程序汇总了其他两个请求的结果。假设的服务器框架(未显示)为每个请求创建一个新的虚拟线程,并handle在该虚拟线程中运行应用程序的代码。应用程序代码依次创建两个新的虚拟线程,通过ExecutorService获取资源:
void handle(Request request, Response response) {
var url1 = ...
var url2 = ...
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}像这样的服务器应用程序,具有简单的阻塞代码,可以很好地扩展,因为它可以使用大量虚拟线程,随意的创建虚拟线程,就像随意的滥交,开销比以前更小,速度比以前更快,滥交好!
正确滥交
众所周知滥交的都很廉价,不需要给她们定制一个家,何况是一个全世界都能随意滥交的,所以说给她们整一个Executors.newVirtualThreadPerTaskExecutor 着实浪费了,直接原地创建虚拟线程就好了,不需要虚拟线程池,虽然您可以大发善心给她们一个家,虽然你在用完她们之后就会把他们赶出去....
肆意的创建虚拟线程,肆意的使用各种会堵塞的操作,一切都由JVM虚拟机去承担,因为她足够廉价!(你自己整的来自native的会堵塞的代码就不要肆意了,会把她们弄坏的
无聊的测试
import kotlinx.coroutines.*
import kotlin.system.measureTimeMillis
fun main() {
repeat(10) {
rp(10000)
}
}
fun rp(size: Int) {
val coroutineTime = measureTimeMillis {
runBlocking {
val jobs = List(size) {
launch {
delay(1000)
}
}
jobs.forEach { it.join() }
}
}
println("Time taken by Kotlin coroutines: $coroutineTime ms")
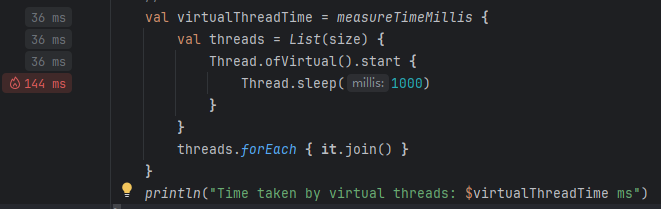
// Measure time for virtual threads
val virtualThreadTime = measureTimeMillis {
val threads = List(size) {
Thread.ofVirtual().start {
Thread.sleep(1000)
}
}
threads.forEach { it.join() }
}
println("Time taken by virtual threads: $virtualThreadTime ms")
}Time taken by Kotlin coroutines: 1134 ms
Time taken by virtual threads: 1100 ms
Time taken by Kotlin coroutines: 1061 ms
Time taken by virtual threads: 1038 ms
Time taken by Kotlin coroutines: 1014 ms
Time taken by virtual threads: 1044 ms
Time taken by Kotlin coroutines: 1018 ms
Time taken by virtual threads: 1022 ms
Time taken by Kotlin coroutines: 1016 ms
Time taken by virtual threads: 1016 ms
Time taken by Kotlin coroutines: 1010 ms
Time taken by virtual threads: 1010 ms
Time taken by Kotlin coroutines: 1006 ms
Time taken by virtual threads: 1021 ms
Time taken by Kotlin coroutines: 1006 ms
Time taken by virtual threads: 1013 ms
Time taken by Kotlin coroutines: 1020 ms
Time taken by virtual threads: 1014 ms
Time taken by Kotlin coroutines: 1021 ms
Time taken by virtual threads: 1017 ms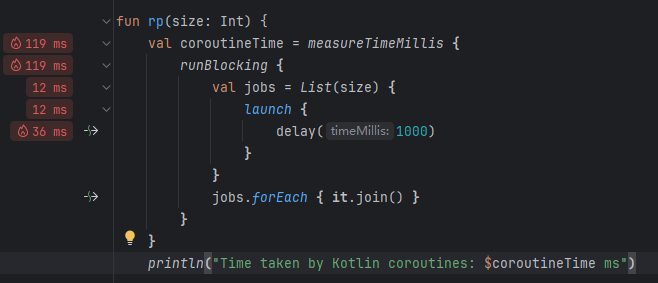
总结
1,线程ID在虚拟线程中的获取
新方法
Thread.threadId()返回线程的标识符。之前的方法Thread.getId()已弃用。(=_=)2,虚拟线程具有固定优先级
Thread.NORM_PRIORITY。Thread.setPriority(int)方法对虚拟线程没有效果。此限制可能会在未来版本中重新讨论。3,虚拟线程不支持
ThreadGroup,因为滥交的一般不被认可,可怜!在虚拟线程上调用Thread.getThreadGroup()返回名为"VirtualThreads"的没鸟用的ThreadGroup。Thread.Builder也不支持定义虚拟线程的ThreadGroup。4,虚拟线程不支持
stop()、suspend()或resume()方法。在虚拟线程上调用这些方法时会引发异常。5,JNI 定义了一个新函数,
IsVirtualThread来测试某个对象是否是虚拟线程。JNI 规范的其他部分没有变化。
进阶情况
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = esvc.submit(() -> findUser());
Future<Integer> order = esvc.submit(() -> fetchOrder());
String theUser = user.get(); // Join findUser
int theOrder = order.get(); // Join fetchOrder
return new Response(theUser, theOrder);
}虽又得看一个烦人的示例,照顾一下不知道使用场景的宝宝吧~上面的代码在正常情况下有3钟情况:
findUser爆了,在user.get()的时候就会喜提异常,fetechOrder却依旧会运行?好情况是fetchOrder了寂寞,因为根本没用到,坏情况就是蝴蝶效应的爆炸,把其它业务也干寄了假设
findUser得花很长时间才能返回,但是fetchOrder很快就爆了,这种情况下还继续运行findUser就是浪费资源,你说你把fetchOrder和findUser调用顺序反过来,孩子你无敌了。假设有人把
handle给结束了,可是呢findUser和fetchOrder都在运行,这又是一种浪费(内存不值钱的回旋镖打某些人头上了)
我们的宝宝巴士Java贴心的提供了别人家协程也有的操作,
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future<String> user = scope.fork(() -> findUser());
Future<Integer> order = scope.fork(() -> fetchOrder());
scope.join(); // Join both forks
scope.throwIfFailed(); // ... and propagate errors
// Here, both forks have succeeded, so compose their results
return new Response(user.resultNow(), order.resultNow());
}
}与原始示例相比,理解此处涉及的线程的生命周期很容易:在所有条件下,它们的生命周期都局限于词汇范围,即try-with-resources语句的主体。此外,使用StructuredTaskScope可确保许多有价值的属性:
如果
findUser()/fetchOrder()爆炸,则另一个将被取消。(这由策略ShutdownOnFailure,当然大傻春你也可以用别的策略,比如整一个爆了就rm -rf /*,有哪些策略呢?)如果正在运行的
handle()在调用之前或期间被中断join(),则当线程退出范围时,两个子任务都会自动取消。上述代码具有清晰的结构:设置子任务,等待它们完成或被取消,然后决定是否成功(并处理已经完成的子任务的结果)或失败(并且子任务已经完成,所以没有什么需要清理的)。
这个涉及的概念的是结构化编程~~~就是把代码写的层次清晰的...
不是所有的项目都能无缝切换到虚拟线程,例如mysql/8就不支持大量的同步语句块在mysql/9被修正,请注意版本!