sec2026
1 题目概述
本题基于 Godot 4.5 Android 客户端构建,核心逻辑由 libsec2026.so 与 libgodot_android.so 共同完成。静态 APK 资源并不足以直接完成分析,原因在于:一方面,关键 SO 在运行态才完成解密与重定位;另一方面,保护模块同时部署了反调试、反注入、代码完整性校验与多线程检测机制。因此,本题的正确解法并不是单点逆向,而是先完成运行时环境接管、再恢复脚本与原生逻辑、最后分别求解 Part1 / Part2 / Part3。
从完整分析过程看,题目可拆为四个阶段:
- 运行时 Dump 与 SO 修复。
- 反调试与检测机制识别及绕过。
- GDScript / GDExtension / Godot 场景逻辑还原。
- 三个 Part 的触发条件恢复与 flag 生成算法分析。
2 整体解题路线
2.1 总体策略
思路清晰,分析无忧,首先尝试直接静态分析 APK,会同时遇到三类障碍:
- so 运行时加载、修正、保护,磁盘文件不可直接作为最终分析对象。
- 保护模块存在多线程反调试与自校验,直接在目标 so 上做 inline patch 会被立即发现。
- 部分高层逻辑位于 Godot 的
.gdc字节码与场景节点交互中,必须结合 Godot API 与运行时对象进行还原。
因此整体策略为:
- 先以 Frida spawn 模式接管进程启动早期阶段(
bypass_sec2026.js铺路)。
- 拦截退出路径并在目标 so 完成加载后进行内存 dump(
dump-so.ts奠基)。
- 对 dump 的 so 进行结构修复,恢复到可被 IDA / Ghidra 正常分析的状态。
- 结合 Godot 引擎接口、GDScript token 表与运行时脚本对象,尽可能恢复各Part逻辑。
- 在不修改 so 代码段的前提下,仅通过 RW 段重定向、线程冻结、运行时对象调用等方式完成反检测绕过与题目求解。
2.2 关键结论先行
最终解题过程中最重要的结论有三点:
| 关键问题 | 结论 |
| 为什么常规 Frida inline hook 不稳定 | 子进程通过 fork + ptrace 对主进程 .text 做完整性校验,任何代码段修改都会暴露 |
| 为什么仅 hook libc 不够 | 关键退出、计时、文件读取走 SVC #0,直接绕过 libc hook |
| 稳定绕过点在哪里 | RW 调度表、spawn 早期接管、冻结校验子进程、以及只做运行时对象层调用 |
3 运行时 Dump 与 so 修复
3.1 为什么必须从内存 Dump
针对决赛,必须从运行时内存中 dump 两个关键 SO:libsec2026.so和libgodot_android.so。原因在于,SO 可能经历了解壳、重定位修正以及保护逻辑注入;磁盘态文件既不完整,也无法反映运行时真实控制流。
3.2 进程保活与退出路径拦截
应用在检测到 Frida 注入后会主动退出,因此第一步不是求解算法,而是保活进程。实验中拦截了以下退出路径:
| 拦截目标 | 方法 | 处理策略 |
| _exit / exit | Interceptor.replace | 阻止退出并记录调用来源 |
| kill | Interceptor.replace | 阻止信号杀进程 |
| abort | Interceptor.replace | 改为挂起,保留现场 |
| raise | Interceptor.replace | 阻止主动发送终止信号 |
| System.exit | Java implementation 替换 | 阻止 Java 层退出 |
| Process.killProcess | Java implementation 替换 | 阻止 Java 层 kill |
| ptrace | 运行时替换 | 降低反调试效果 |
| fgets | 运行时替换 | 防止通过 /proc/self/status 检测 TracerPid |
这些拦截更多用于早期接管与 dump 阶段。进入 libsec2026.so 的核心保护区后,单纯依赖这些 libc/Java 层 hook 并不足以稳定绕过全部检测,原因会在后文详细解释。
3.3 动态加载捕获
目标 SO 并非启动即加载,因此采用以下方式捕获加载时机:
- Hook
android_dlopen_ext作为主入口。
- Hook
dlopen作为兜底。
- 检测到目标库加载完成后延时约 200ms,再执行 dump,确保 linker 已完成重定位。
3.4 安全 Dump 策略
由于目标 so 内存可能不连续、页权限不统一,最终使用“快速尝试 + 安全逐页 dump”的两级策略。
3.4.1 快速 Dump
直接读取模块地址范围并写出文件,适合小型且连续映射的 so。
3.4.2 逐页安全 Dump
核心步骤如下:
- 枚举模块全部可读内存段。
- 按地址排序,保证输出布局与虚拟地址一致。
- 以 4KB 为单位逐页读取。
- 对可读页写真实内容;读取失败页用零页填充。
- 对未映射空洞同样做零填充。
- 保证最终文件大小与模块声明大小一致。
- 使用原生
fopen/fwrite/fclose避免 JS 层 I/O 不稳定。
最终生成的 dump 文件可用于后续结构修复。
3.5 Dump 后 so 修复
内存 dump 得到的 so 无法直接被 IDA/Ghidra 正常加载,主要问题包括:
- LOAD 段
p_offset与运行时地址混淆。
- section header 缺失。
- GOT 已被重定位覆盖。
init_array被改写。
由于通用 SoFixer 无法很好处理这种分段 dump 结果,因此另外编写修复脚本恢复 ELF 结构,使 libsec2026.so 与 libgodot_android.so 可以进入正常逆向流程。
4 反调试与检测机制分析
4.1 初始化后的三线程检测架构
通过函数_dl_unw_init_local进入,启动保护模块会采用 pthread_create 启动三个检测线程:
| 线程 | 入口 | 作用 |
| Thread 1 | sub_9C654 | fork + ptrace 反调试 |
| Thread 2 | loc_9CDC4 | /proc 文件系统扫描 |
| Thread 3 | sub_9B7D8 | 反外挂 / 反调试检测 |
4.2 反调试检测
sub_9C654 是一个典型的反调试(Anti-Debugging)检测器,主要使用 fork 和 ptrace 进行自我附加和系统调用跟踪。它的整体控制流被高度混淆(控制流平坦化 / 状态机),即通过更新一个状态变量,不断从查表分发入口跳转到对应的功能块,借助AI进行完全分析,它分为5个阶段:
- 进程分裂:主进程fork后子进程独立于主进程扮演一个看门狗的角色!
- 双重 ptrace 跟踪:子进程会对父进程发起
ptrace(PTRACE_ATTACH, pid, ...)或类似的追踪请求。
原理:Linux 中一个进程同一时刻只能被一个调试器 ptrace。如果此时已经有一个真实调试器(如 IDA 或 LLDB)挂载在游戏主进程上,子进程的 ptrace 请求就会失败报错。反过来,如果子进程成功挂载到了父进程,那外面的黑客就再也无法用调试器附加进来了(会报 Operation not permitted)。- 系统调用拦截(PTRACE_SYSCALL):子进程并没有只是简单休眠,它向父进程发送了
ptrace(PTRACE_SYSCALL, pid, 0, 0)(对应参数常量 0x10)。
原理:这使得父进程在每次执行任何 Syscall(如 read, write, open)前后,都会被挂起(STOP),并将控制权交给守护进程。
- 事件捕获与响应循环:子进程进入了一个死循环,其核心逻辑是调用
waitpid(父进程PID, &status, 0)阻塞等待父进程的状态改变。当父进程因为系统调用或受到信号被挂起时,waitpid会返回,守护进程通过检查status(汇编层可看到通过TST W27, #0x7F判断信号特征),来判断父进程是正常系统调用,还是遇到了异常(如调试器插入断点引发的SIGTRAP)。如果认为可疑,它会调用sub_95CC0函数。这个函数底层调用了ptrace(PTRACE_GETREGSET, pid, 1026, ®s)。
原理:获取父进程的完整寄存器上下文。原理猜测如果此时检测到PC寄存器附近被修改为0x00 0x00 0x20 0xD4(BRK 硬件指令),或是检测到了硬件调试寄存器被设置,就能确认游戏被动态修改或下了断点。
- 惩罚执行:ptrace附加失败又或者监控到了调试器的存在,状态机就会把流导向
0x9cae4分支,最终调用exit(0)或exit(1)(调用了_exit函数地址off_1669B0),强行将子进程和父进程一并结束,导致游戏闪退,从而达到反调试的目的。它还会调用__stack_chk_fail来主动触发栈崩溃,增加定位崩溃点的难度。
4.3 文件系统的调试状态检测
0x9cdc4 及以后是检测器的第二阶段:基于 /proc 文件系统的线程与调试状态检测。第一阶段利用了 fork 和 ptrace 进行自我附加和系统调用拦截,而第二阶段则作为第一阶段的补充,通过周期性的主动扫描来捕捉动态调试。
进入休眠(定时扫描准备):
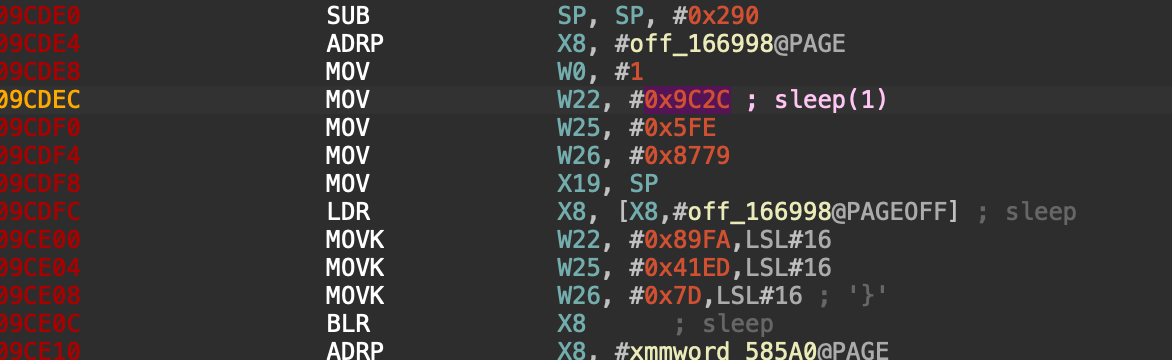
在 0x9cdec 处,它调用了 sleep(1)。这意味着该检测器在一个单独的线程 / 循环中周期性地执行,通过定时休眠(1 秒)来控制扫描频率,以防止过度占用 CPU 被发现,并维持一个持续的守护状态。
枚举线程目录(/proc/self/task 扫描):
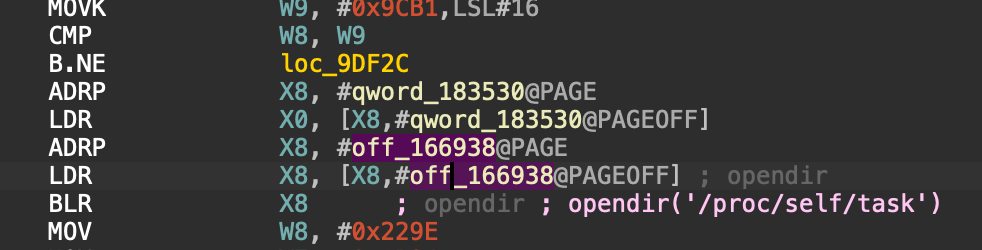
唤醒后,状态机导向了 0x9d050 的 opendir() 调用。它通过在运行时解密出一个路径字符串(基于混淆算法,实际指向 /proc/self/task 或 /proc/pid/task)打开当前进程的线程目录。

接着在 0x9da0c 处调用 readdir()。通过循环,它会逐一遍历本进程的所有子线程。
读取并解析 stat 或 status(异常与调试状态检测):
每遍历到一个线程的 TID,它就会组合出类似 /proc/self/task/[tid]/stat(或 status / wchan)的文件路径
在 0x9daf4 等位置,调用 sub_9C4FC / sub_9AD3C 等辅助解析函数。
检测原理:
- TracerPid 检测:在 Linux 系统中,如果一个进程 / 线程正在被调试,它的
/proc/pid/status文件中的TracerPid字段会变成对应调试器的 PID(而不是 0)。
- State 检测:当进程处于断点或因为
ptrace而暂停时,它的状态会变成T (tracing stop)或者t (tracing stop)。检测器通过读取stat文件的第 3 个字段来识别异常停止的状态。
- 另外,它可能还会检查特定线程的名字、挂起地址(
wchan中是否有ptrace_stop)来确认自己是否处于调试环境。
4.4 反外挂 / 反调试检测
sub_9B7D8 同样是一个高度隐蔽且执行流被严重混淆(控制流平坦化 / 状态机)的检测器线程(Detector Thread)。它不依赖于 libc 层的标准文件操作库函数,而是通过底层的内联系统调用(SVC 0)直接与操作系统内核通信,以绕过常规的 Inline Hook 或 PLT/GOT Hook。该模块的主要目标是读取和检测环境中的高危特征(如 /proc 下的文件或进程状态)。
隐蔽与初始化:
进入该函数后,检测器会进行自我隐藏和降级,避免对游戏的主逻辑造成性能影响或引起分析人员注意:
- 延迟执行:通过调用
sleep(3),推迟自己的首次检测动作。这种 “延时启动” 策略常被用来避开调试器刚附加时的密集扫描期。
- 降低调度优先级:调用
setpriority(PRIO_PROCESS, 0, 19)。将当前检测线程的优先级拉低至最低级(19),确保它在后台静默运行,不会抢占 CPU 时间片。
动态字符串解密:
为了对抗静态分析和静态字符串检索,检测器所需的文件路径并没有硬编码在 .rodata 段中。它首先使用 __memcpy_chk 将一段加密数据(位于 unk_1682D0)复制到栈上([X19, #0xE0] 附近)。随后,程序利用 ARM64 的 NEON 向量寄存器(V 系列寄存器)执行了双重 XOR 解密算法:
LDR Q2, [X19,#0x10]
EOR V0.16B, V0.16B, V2.16B ; 第一层异或,基于运行时动态 Key
EOR V0.16B, V1.16B, V0.16B ; 第二层异或,基于数据段的 Key
STR Q0, [X19,#0xE0]自我保护及检测:
分析发现,他调用了 mprotect() 给自身的关键内存页重新设置权限(如 RX),猜测具体作用是防止被动态插入断点,由于动态解密无法静态还原文件路径,但在 Android 游戏安全的语境下,结合 openat + read 的连招模式,再次猜测可能是maps或者smaps之类的扫描,因为我的frida已经可以正常注入了,这里不再深入研究。
5 资源脚本与 Godot 层分析
5.1 GDScript 字节码恢复
与初赛一致,PCK 加密方式没有本质变化,但决赛版本的.gdc字节码直接用现有工具反编译会出现错误。问题关键在于 token type 到操作符的映射并不是工具默认假设的值。
后续通过在 libgodot_android.so 中定位GDScript Token::Type枚举表,恢复了正确的 token 语义,并据此修复了自研反编译脚本,得到正确的 Part1 脚本算法。
其中一个关键修正为:
- 错误反编译:
_v = ((_v - 3) % (_v * 5)) & 255
- 正确逻辑:
_v = ((_v << 3) | (_v >> 5)) & 255
也即,原逻辑是 8-bit 左旋 3 位,而不是算术表达式。
5.2 GDExtension API 表定位
通过分析 extension_init 到 API 加载器的调用链,定位到 GDExtension 的函数指针装载过程。其特点是:
- 通过
get_proc_address("api_name")动态获取 Godot 接口(熟读godot引擎这块)。

- API 指针连续存入 .bss/.data。
- 错误字符串中直接泄露 API 名称。
- 该加载器早于反调试线程启动,且未被 CFF 保护。
提取关键特征编写一个脚本前向搜索所有的函数:
import idautils, idc, re
func_start = 0xAAE98
func_end = func_start + 10144
# 收集所有 ADRL/ADR + API 名称字符串
adrl_list = []
for head in idautils.Heads(func_start, func_end):
mnem = idc.print_insn_mnem(head)
if mnem in ("ADRL", "ADR"):
op1 = idc.get_operand_value(head, 1)
s = idc.get_strlit_contents(op1)
if s:
s = s.decode('utf-8', errors='replace')
# 过滤掉错误消息和非 API 字符串
if "Unable to load" in s or "Cannot load" in s or "src\\" in s:
continue
if "ERROR:" in s or s == "init":
continue
adrl_list.append((head, s))
# 前向搜索: 从 ADRL 往后找第一个带 off_/qword_ 的 STR
for addr, name in adrl_list:
nxt = addr
for _ in range(12):
nxt = idc.next_head(nxt)
if nxt > func_end:
break
if idc.print_insn_mnem(nxt) == "STR":
op1 = idc.print_operand(nxt, 1)
m = re.search(r'(off_|qword_)([0-9A-Fa-f]+)', op1)
if m:
offset = int(m.group(2), 16)
print(f"0x{offset:06X} | {name}")
break5.3 为什么选择 variant_call
分析发现,该版本的 classdb_get_method_bind 必须传入真实哈希值,hash=0 不能绕过校验,因此不适合作为通用frida去做主动调用实现动态调试的手段。
// classdb_get_method_bind(StringName class, StringName method, uint32_t hash)
__int64 sub_3C14680(__int64 a1, __int64 a2, __int64 a3 /*hash*/)
{
// 首次查找: 用提供的 hash 严格匹配
v5 = sub_3C3B654(class_sn, method_sn, a3 /*hash*/, &compat_flag, 0);
// 如果失败且 compat_flag 被设置, 尝试兼容哈希表
if (!v5 && (compat_flag
&& sub_3C1EEB8(class_sn, method_sn, a3, &new_hash)
&& (v5 = sub_3C3B654(class_sn, method_sn, new_hash, ...)) != 0))
{
// 找到了兼容哈希
}
else if (!v5)
{
// 全部失败 → 返回 NULL
return 0;
}
return v5; // 返回 MethodBind*
}相比之下,variant_call 通过 StringName 查找方法,可直接按方法名调用对象接口,完全绕过 ClassDB 哈希限制,因此成为最灵活稳定的 Godot 调用方案。
6 variant_call 验证
写一段简单的脚本,让扫描到的方块围着我们转,效果验证成功!variant_call成为最灵活稳定的 Godot 调用方案
引力中心:
飞起来!
7 Part1 分析
7.1 场景逻辑与触发条件
绿色方块 Trigger2 位于房顶(),正常驾驶路径无法直接到达,因此需要脱离正常物理路径求解。
var gB=null,sB=null;
function setup(){
var g=Process.findModuleByName("libgodot_android.so"),s=Process.findModuleByName("libsec2026.so");
if(!g||!s){setTimeout(setup,500);return;}
gB=g.base;sB=s.base;
var frame=0;
Interceptor.attach(gB.add(0x106dcdc),{onEnter:function(){
frame++;
if(frame===600) findVehicle();
}});
console.log("[*] Will search at frame 600");
}
function rA(o){return sB.add(o).readPointer();}
function findVehicle(){
try{
var _get_singleton=new NativeFunction(gB.add(0x3C1371C),'pointer',['pointer']);
var _sn_new=new NativeFunction(gB.add(0x3C12E5C),'void',['pointer','pointer','uint8']);
var _engine_get_ml=new NativeFunction(gB.add(0x36C8768),'pointer',['pointer']);
var _tree_get_root=new NativeFunction(gB.add(0x200E700),'pointer',['pointer']);
var _var_call=new NativeFunction(rA(0x1839F0),'void',['pointer','pointer','pointer','int64','pointer','pointer']);
var _var_nil=new NativeFunction(rA(0x1839E0),'void',['pointer']);
var _var_from_type=new NativeFunction(rA(0x183AD0),'pointer',['int']);
var _str_to_utf8=new NativeFunction(rA(0x183BC0),'int64',['pointer','pointer','int64']);
var _var_stringify=new NativeFunction(rA(0x183A88),'void',['pointer','pointer']);
function makeSN(s){var b=Memory.alloc(8);b.writeU64(0);_sn_new(b,Memory.allocUtf8String(s),0);return b;}
function objV(p){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);var c=_var_from_type(24);var h=Memory.alloc(8);h.writePointer(p);new NativeFunction(c,'void',['pointer','pointer'])(v,h);return v;}
function intV(n){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);var c=_var_from_type(2);var h=Memory.alloc(8);h.writeS64(n);new NativeFunction(c,'void',['pointer','pointer'])(v,h);return v;}
function vc(sv,m,ar){var sn=makeSN(m);var r=Memory.alloc(24);for(var i=0;i<24;i++)r.add(i).writeU8(0);_var_nil(r);var e=Memory.alloc(12);var ap=Memory.alloc(8*Math.max(ar.length,1));for(var i=0;i<ar.length;i++)ap.add(i*8).writePointer(ar[i]);_var_call(sv,sn,ap,ar.length,r,e);return r;}
function vs(v){var g=Memory.alloc(8);g.writeU64(0);_var_stringify(v,g);var l=_str_to_utf8(g,ptr(0),0);if(l<=0)return"?";var b=Memory.alloc(l+1);_str_to_utf8(g,b,l+1);return b.readUtf8String();}
var engine=_get_singleton(makeSN("Engine"));
var tree=_engine_get_ml(engine);
var root=_tree_get_root(tree);
var rv=objV(root);
// 用 variant_call("print_tree_pretty") 打印整棵树!
console.log("[*] Calling print_tree_pretty on root...");
vc(rv,"print_tree_pretty",[]);
// 这会输出到 Godot 的 stdout, 我们用 Frida 看不到
// 改用 get_tree_string_pretty() 返回 String
console.log("[*] Calling get_tree_string_pretty...");
var treeStr = vc(rv,"get_tree_string_pretty",[]);
var s = vs(treeStr);
console.log("=== SCENE TREE ===");
console.log(s);
console.log("=== END ===");
}catch(e){console.log("[ERR] "+e.stack);}
}通过以上的代码走 variant_call 访问场景树,恢复出的关键流程如下:
- Engine singleton → SceneTree → Root。
- 获取 TownScene/InstancePos/car/Body 节点,得到车辆对象。
- 获取 TownScene/Trigger2 节点。
- 读取 Trigger2 的世界坐标。
- 将车辆速度清零。
- 将车辆直接传送至 Trigger2 附近。
- 直接调用 Trigger2 的 _w7() 方法触发 flag。
- 读取 UI 文本得到结果。
7.2 实际求解方式
Part1 的核心并不是破解复杂原生逻辑,而是利用 Godot 运行时对象能力完成“场景导航 + 条件直达”。
最终稳定方案有两种:
- 坐标传送到 Trigger2 附近,再让逻辑自然触发。
- 直接调用 Trigger2 脚本方法 _w7()。
1. Engine singleton → SceneTree → Root Window
2. variant_call(root, "get_node", "TownScene/InstancePos/car/Body") → Vehicle*
3. variant_call(root, "get_node", "TownScene/Trigger2") → Trigger2*
4. variant_call(trigger2, "get_global_position") → (-14.96, 11.67, -3.08)
5. variant_call(vehicle, "set_linear_velocity", Vector3(0,0,0)) → 清速度
6. variant_call(vehicle, "set_global_position", trigger2_pos + Y=1) → 传送!
7. object_call_script_method(trigger2, "_w7", [nil]) → 触发 flag (可选)
8. variant_call(label2, "get_text") → "flag{sec2026_PART1_d9620163}"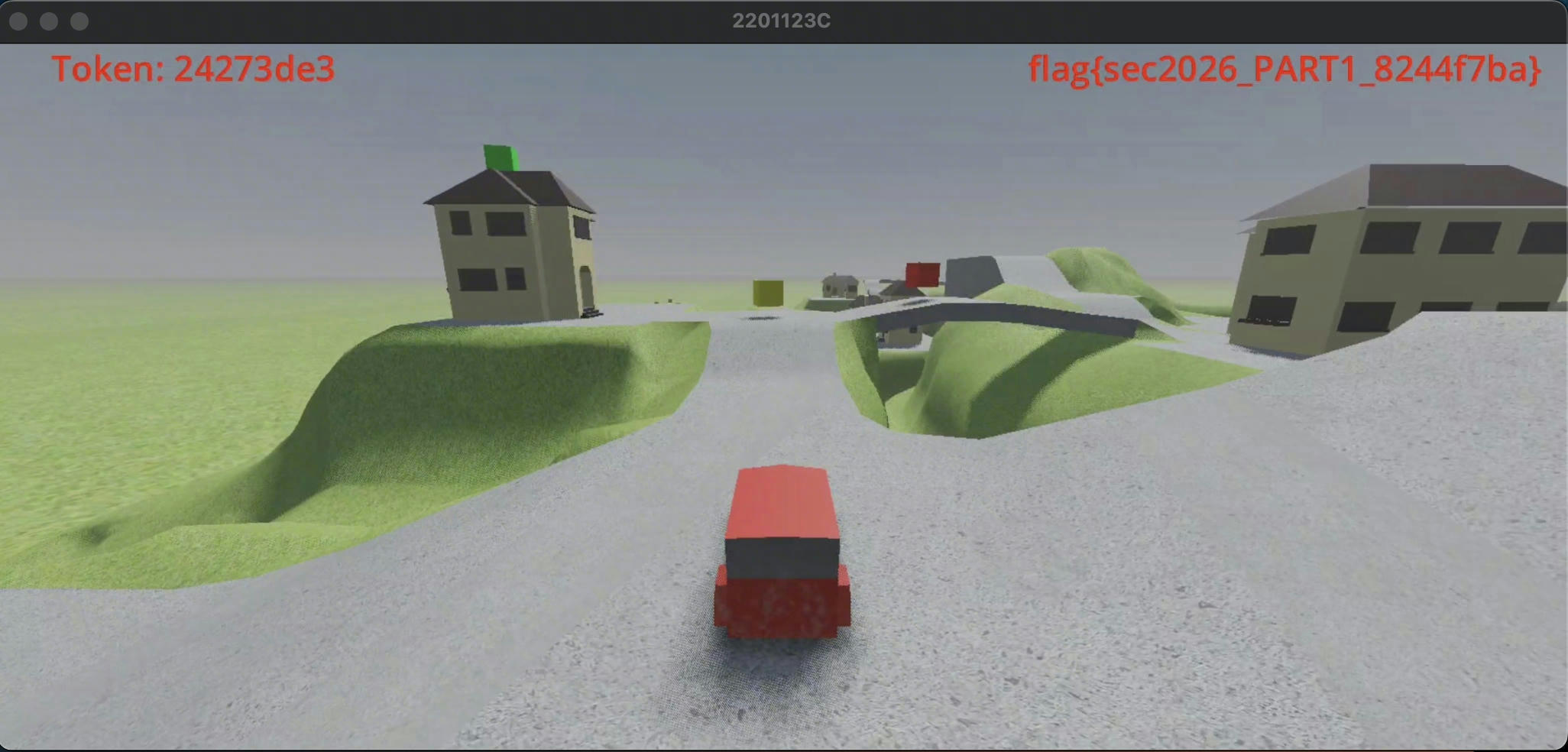
运行中成功读取到:
Label2 text = flag{sec2026_PART1_8244f7ba}
- 同时界面还会显示一个中间 token。
7.3 Part1 算法恢复
在修复 .gdc 反编译后,可以完整还原 Part1 对 token/字节序列的处理逻辑,并据此编写逆算法。换言之,Part1 同时具备“动态直取 flag”与“静态算法恢复”两种完成路径。
8 Part2 分析
8.1 题目机制理解
根据脚本逻辑,Part2 需要在满足碰撞相关前置条件后,再进入指定方块区域,才会输出 flag。
重点在于 Godot Area3D 的两个控制项:
- monitoring:Area 是否主动检测物体进入/离开。
- 与碰撞相关的状态变量:决定 body_entered 信号是否会真正触发。
function doIt(){
try{
var _get_singleton=new NativeFunction(gB.add(0x3C1371C),'pointer',['pointer']);
var _sn_new=new NativeFunction(gB.add(0x3C12E5C),'void',['pointer','pointer','uint8']);
var _engine_get_ml=new NativeFunction(gB.add(0x36C8768),'pointer',['pointer']);
var _tree_get_root=new NativeFunction(gB.add(0x200E700),'pointer',['pointer']);
var _call_script=new NativeFunction(gB.add(0x3C13A68),'void',['pointer','pointer','pointer','int64','pointer','pointer']);
var _var_call=new NativeFunction(rA(0x1839F0),'void',['pointer','pointer','pointer','int64','pointer','pointer']);
var _var_nil=new NativeFunction(rA(0x1839E0),'void',['pointer']);
var _var_from_type=new NativeFunction(rA(0x183AD0),'pointer',['int']);
var _var_to_type=new NativeFunction(rA(0x183AD8),'pointer',['int']);
var _str_new_utf8=new NativeFunction(rA(0x183B60),'void',['pointer','pointer']);
var _var_construct=new NativeFunction(rA(0x183B08),'void',['int','pointer','pointer','int','pointer']);
var _var_destroy=new NativeFunction(rA(0x1839E8),'void',['pointer']);
var _var_stringify=new NativeFunction(rA(0x183A88),'void',['pointer','pointer']);
var _str_to_utf8=new NativeFunction(rA(0x183BC0),'int64',['pointer','pointer','int64']);
function makeSN(s){var b=Memory.alloc(8);b.writeU64(0);_sn_new(b,Memory.allocUtf8String(s),0);return b;}
function objV(p){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);var c=_var_from_type(24);var h=Memory.alloc(8);h.writePointer(p);new NativeFunction(c,'void',['pointer','pointer'])(v,h);return v;}
function npV(ps){var gs=Memory.alloc(8);gs.writeU64(0);_str_new_utf8(gs,Memory.allocUtf8String(ps));var sc=_var_from_type(4);var sv=Memory.alloc(24);for(var i=0;i<24;i++)sv.add(i).writeU8(0);new NativeFunction(sc,'void',['pointer','pointer'])(sv,gs);var np=Memory.alloc(24);for(var i=0;i<24;i++)np.add(i).writeU8(0);var a=Memory.alloc(8);a.writePointer(sv);var e=Memory.alloc(12);_var_construct(22,np,a,1,e);_var_destroy(sv);return np;}
function makeNilV(){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);_var_nil(v);return v;}
function makeStringVar(s){var gs=Memory.alloc(8);gs.writeU64(0);_str_new_utf8(gs,Memory.allocUtf8String(s));var sc=_var_from_type(4);var sv=Memory.alloc(24);for(var i=0;i<24;i++)sv.add(i).writeU8(0);new NativeFunction(sc,'void',['pointer','pointer'])(sv,gs);return sv;}
function makeIntVar(n){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);v.writeU32(2);v.add(8).writeS64(n);return v;}
function makeBoolVar(b){var v=Memory.alloc(24);for(var i=0;i<24;i++)v.add(i).writeU8(0);v.writeU32(1);v.add(8).writeU8(b?1:0);return v;}
function vc(sv,m,ar){var sn=makeSN(m);var r=Memory.alloc(24);for(var i=0;i<24;i++)r.add(i).writeU8(0);_var_nil(r);var e=Memory.alloc(12);var ap=Memory.alloc(8*Math.max(ar.length,1));for(var i=0;i<ar.length;i++)ap.add(i*8).writePointer(ar[i]);_var_call(sv,sn,ap,ar.length,r,e);return{ret:r,err:e.readU32()};}
function vs(v){var g=Memory.alloc(8);g.writeU64(0);_var_stringify(v,g);var l=_str_to_utf8(g,ptr(0),0);if(l<=0)return"?";var b=Memory.alloc(l+1);_str_to_utf8(g,b,l+1);return b.readUtf8String();}
function varToObj(v){try{if(!v||v.isNull()||v.readU32()!==24)return ptr(0);var d=_var_to_type(24);var o=Memory.alloc(8);o.writePointer(ptr(0));new NativeFunction(d,'void',['pointer','pointer'])(o,v);return o.readPointer();}catch(e){return ptr(0);}}
var engine=_get_singleton(makeSN("Engine"));
var tree=_engine_get_ml(engine);
var root=_tree_get_root(tree);
var rootVar=objV(root);
// 取节点
function getNode(path){return varToObj(vc(rootVar,"get_node_or_null",[npV(path)]).ret);}
var t2Ptr=getNode("TownScene/Trigger2");
var t3Ptr=getNode("TownScene/Trigger3");
var t4Ptr=getNode("TownScene/Trigger4");
var label2Ptr=getNode("TownScene/Label2");
// 检查碰撞状态
function checkColl(label){
console.log("\n--- "+label+" ---");
for(var ti=3;ti<=4;ti++){
var tP=getNode("TownScene/Trigger"+ti);
if(tP.isNull()) continue;
var tV=objV(tP);
var m=vs(vc(tV,"is_monitoring",[]).ret);
// 检查 CollisionShape3D
var cc=parseInt(vs(vc(tV,"get_child_count",[]).ret));
var csDisabled="?";
for(var ci=0;ci<cc;ci++){
var cP=varToObj(vc(tV,"get_child",[makeIntVar(ci)]).ret);
if(cP.isNull()) continue;
var cV=objV(cP);
if(vs(vc(cV,"get_class",[]).ret)==="CollisionShape3D"){
csDisabled=vs(vc(cV,"is_disabled",[]).ret);
}
}
console.log(" Trigger"+ti+": monitoring="+m+" collShape.disabled="+csDisabled);
}
}
function callW7(tPtr){
var sn=makeSN("_w7");var nv=makeNilV();
var a=Memory.alloc(8);a.writePointer(nv);
var r=makeNilV();var e=Memory.alloc(12);
_call_script(tPtr,sn,a,1,r,e);
return e.readU32();
}
function tickAll(n){
for(var ti=1;ti<=4;ti++){
var tP=getNode("TownScene/Trigger"+ti);
if(tP.isNull()) continue;
var gx=varToObj(vc(objV(tP),"get",[makeStringVar("_gx")]).ret);
if(!gx.isNull()){
var gxV=objV(gx);
for(var i=0;i<n;i++) vc(gxV,"Tick",[]);
}
}
}
// 找车
var ipPtr=getNode("TownScene/InstancePos");
var vehiclePtr=ptr(0);
if(!ipPtr.isNull()){
function findVB(nV,d){
if(d>5)return null;
var cc=parseInt(vs(vc(nV,"get_child_count",[]).ret));
for(var i=0;i<cc;i++){
var cP=varToObj(vc(nV,"get_child",[makeIntVar(i)]).ret);
if(cP.isNull())continue;
var cV=objV(cP);
if(vs(vc(cV,"get_class",[]).ret)==="VehicleBody3D")return cP;
var r=findVB(cV,d+1);if(r)return r;
}
return null;
}
vehiclePtr=findVB(objV(ipPtr),0);
}
console.log("[*] Vehicle: "+vehiclePtr);
console.log("[*] Token: "+vs(vc(objV(getNode("TownScene/Label")),"get_text",[]).ret));
// === 初始状态 ===
checkColl("INITIAL STATE (no trigger fired)");
// === Tick 100次 (无触发) ===
console.log("\n[*] Ticking all 100 times...");
tickAll(100);
checkColl("AFTER 100 Ticks (no trigger)");
// === 触发 Part1 ===
console.log("\n[*] Triggering Part1 (Trigger2._w7)...");
callW7(t2Ptr);
var fl1=vs(vc(objV(label2Ptr),"get_text",[]).ret);
console.log("[*] Part1: "+fl1);
// tick 让 native 处理状态变化
tickAll(200);
checkColl("AFTER Part1 + 200 Ticks");
// === 传送车到 Trigger2 (模拟到达) ===
if(vehiclePtr&&!vehiclePtr.isNull()){
var t2Pos=vc(objV(t2Ptr),"get_global_position",[]);
vc(objV(vehiclePtr),"set_global_position",[t2Pos.ret]);
console.log("\n[*] Teleported vehicle to Trigger2");
tickAll(200);
checkColl("AFTER teleport to Trigger2 + 200 Ticks");
}
// === 传送车到 Trigger3 (不触发 _w7) ===
if(vehiclePtr&&!vehiclePtr.isNull()){
var t3Pos=vc(objV(t3Ptr),"get_global_position",[]);
vc(objV(vehiclePtr),"set_global_position",[t3Pos.ret]);
console.log("\n[*] Teleported vehicle to Trigger3");
tickAll(200);
checkColl("AFTER teleport to Trigger3 + 200 Ticks");
}
// === 触发 Part2 ===
console.log("\n[*] Triggering Part2 (Trigger3._w7)...");
callW7(t3Ptr);
var fl2=vs(vc(objV(label2Ptr),"get_text",[]).ret);
console.log("[*] Part2: "+fl2);
tickAll(200);
checkColl("AFTER Part1+Part2 + 200 Ticks");
// === 传送车到 Trigger4 ===
if(vehiclePtr&&!vehiclePtr.isNull()){
var t4Pos=vc(objV(t4Ptr),"get_global_position",[]);
vc(objV(vehiclePtr),"set_global_position",[t4Pos.ret]);
console.log("\n[*] Teleported vehicle to Trigger4");
tickAll(200);
checkColl("AFTER teleport to Trigger4 + Part1+Part2 + 200 Ticks");
}
// === 大量 Tick ===
console.log("\n[*] Mass tick 2000...");
tickAll(2000);
checkColl("AFTER 2000 more Ticks");
// === 检查最终 Label2 ===
var finalL2=vs(vc(objV(label2Ptr),"get_text",[]).ret);
console.log("\n[*] Label2 final: "+finalL2);
console.log("\n=== EXPERIMENT DONE ===");
}catch(e){console.log("[!] "+e.stack);}
}
setTimeout(setup,1000);编写脚本扫描PART2和PART3的碰撞状态,分析得到:
| monitoring | CollisionShape | 需要开启的因素 | |
| Part2 | true | disabled | 1 个:启用 CollisionShape |
| Part3 | false | disabled | 2 个:启用 monitoring + 启用 CollisionShape |
8.2 分析方法
Part2 主要通过脚本层还原条件,再结合运行时对象调用控制节点状态,最终使区域进入事件成立,并读取界面文本中的 flag。
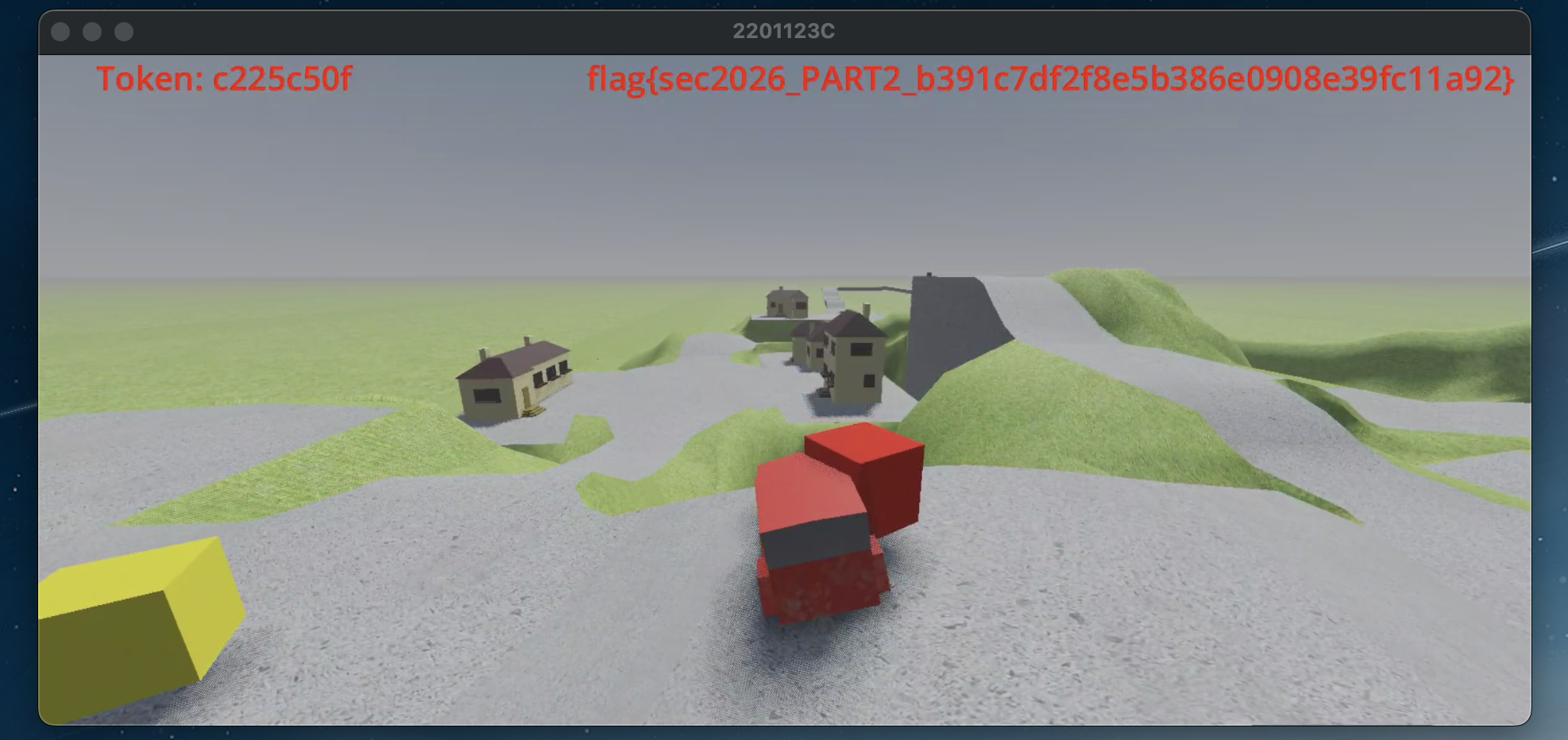
从原稿恢复出的 flag 拼接格式为:flag{sec2026_PART2_<rv>}
这表明其最终生成仍在脚本层完成,原生层更多承担保护与部分辅助逻辑。
8.3 与反调试绕过的关系
Part2 的关键经验是:在完成总体保活后,后续题目求解尽量走“引擎对象层”而非“安全模块 patch 层”。这也是为什么在前面先要把反调试绕过做稳,否则后面即便逻辑看懂,也无法稳定复现去做算法的验证。
8.4 算法分析
结论先行,Part2 是一个基于 自定义 SPN (Substitution-Permutation Network) 分组密码 的加密挑战。玩家触发红色方块后,游戏生成一个 8 字符 hex token,通过 native 层的 GameExtension.Process()方法加密,产生 32 字符 hex 的 flag 后缀。
GDScript 层:
# trigger3.gd
func _w7(_ar):
var _raw = str(_lt.text).substr(7) # 去掉 "Token: " → 8 hex chars
var _buf = _raw.to_utf8_buffer() # 8 bytes ASCII
var _rv = _gx.Process(_buf) # 调用 native Process()
_lb.text = "flag{sec2026_PART2_" + _rv + "}"libsec2026.so:
sub_97704 (Process 回调入口)
├── variant_to_native(input)
├── sub_A936C (加密入口)
│ ├── memcpy(buf, input, 8) # 复制 token 前 8 字节
│ ├── memcpy(buf+8, input, 8) # 复制一次,形成 16 字节明文
│ ├── 加载密钥材料 @0x58550 (16字节) 和 IV @0x58600 (16字节)
│ ├── sub_A7900(ctx, key, iv) # 密钥调度初始化
│ │ ├── sub_A7DE8(ctx, key) # 密钥扩展 (CFF 混淆)
│ │ └── memcpy(ctx+192, iv) # 复制 IV
│ ├── sub_A7194(ctx, pt, 16) # 加密 (CFF 混淆)
│ └── hex_encode(output) # 输出 32 字符 hex
└── set_return_value(result)关键发现:
- 输入: 8 字节 ASCII token 被复制两次,形成 16 字节明文
token || token
- 核心函数:
sub_A7194(加密) 和sub_A7DE8(密钥扩展) 均被 CFF 混淆
- CFF 特征:
BR Xn间接跳转 + 状态变量驱动的 switch 分发,IDA 无法有效反编译
8.4.1 S-box 提取
S-box 位于 BSS 段偏移 0x183700 (256 字节)。静态二进制中全为 0,运行时由初始化线程填充。
var sbox = sB.add(0x183700);
var SBOX = [];
for (var i = 0; i < 256; i++) SBOX[i] = sbox.add(i).readU8();提取结果:
S-box (hex, 16×16):
f1 12 5d c6 a7 8a 6a 48 da 0f 11 3b 3c b3 2d 27
64 2a d3 13 dc 68 c9 cf 17 2e d0 cd c2 b7 c7 f5
66 9b 1c 73 e0 56 dd a5 3a c8 3d d2 b0 e5 ee ec
82 df 43 b8 61 50 ef b1 35 72 8f c3 ea 84 ae 86
67 23 c4 a6 07 4d ed b4 24 7b 22 e6 ba 76 db 9a
49 77 30 eb 97 a0 60 1b 51 58 fb 52 7e 69 7f f8
15 bf bb 28 a8 70 55 31 b9 ab 7c 80 fe 53 d1 05
93 fa 6d f7 ce 45 b5 02 21 bc 4b 19 5e 79 4a 90
e7 47 98 16 6b 20 5a 89 d7 42 f2 ca ff a9 0e a2
46 c5 e9 9e 18 0c 7a 59 54 5f 32 c1 e4 65 44 9d
ad 63 b2 cb 4c 2f a1 1f 9f 4e 04 e3 39 0d d9 71
fc 34 78 8d f4 33 7d f9 36 25 bd 38 b6 de 75 5c
83 9c 8b 40 d4 aa 1d 06 00 a4 6c 88 a3 3f cc f3
d5 be 81 0b 37 94 14 8c 2b 92 fd 1e e1 03 d6 4f
c0 09 74 5b e2 62 af 10 6e 85 f6 96 8e 6f 08 f0
99 95 0a 1a ac 91 d8 29 26 3e e8 01 2c 87 41 578.4.2 unicorn辅助分析
由于 CFF 混淆使得静态逆向极其困难,采用 Unicorn CPU 模拟器 作为分析工具,直接加载二进制并执行原始机器码。
from unicorn import *
from unicorn.arm64_const import *
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
# 加载 SO 到 0x0
mu.mem_map(0, 8*1024*1024, UC_PROT_ALL)
mu.mem_write(0, binary_data)
# 栈空间
mu.mem_map(0x200000000, 16*1024*1024, UC_PROT_ALL)
mu.reg_write(UC_ARM64_REG_SP, 0x200000000 + 16*1024*1024 - 0x1000)
# TLS (线程局部存储)
mu.mem_map(0x300000000, 0x10000, UC_PROT_ALL)
mu.reg_write(UC_ARM64_REG_TPIDR_EL0, 0x300000000)
# Mock 函数 (RET 指令)
mu.mem_map(0x400000000, 0x1000, UC_PROT_ALL)
mu.mem_write(0x400000000, b'\xc0\x03\x5f\xd6') # RET
# 手动写入 S-box 到 BSS
mu.mem_write(0x183700, SBOX)
# GOT 表: __memcpy_chk → mock memcpy
mu.mem_write(0x166920, struct.pack('<Q', MEMCPY_HOOK_ADDR))密钥调度初始化:
# 调用 sub_A7900(ctx, key_ptr, iv_ptr)
mu.reg_write(UC_ARM64_REG_X0, CTX_ADDR)
mu.reg_write(UC_ARM64_REG_X1, 0x58550) # 密钥材料
mu.reg_write(UC_ARM64_REG_X2, 0x58600) # IV
mu.reg_write(UC_ARM64_REG_LR, MOCK_RET)
mu.emu_start(0xA7900, MOCK_RET)
# ctx[0..191] = 密钥调度 (12×16字节)
# ctx[192..207] = IV
saved_ctx = bytes(mu.mem_read(CTX_ADDR, 256))加密执行:
# 调用 sub_A7194(ctx, plaintext, 16)
mu.mem_write(CTX_ADDR, saved_ctx) # 恢复上下文
mu.mem_write(PT_ADDR, plaintext_16)
mu.reg_write(UC_ARM64_REG_X0, CTX_ADDR)
mu.reg_write(UC_ARM64_REG_X1, PT_ADDR)
mu.reg_write(UC_ARM64_REG_X2, 16)
mu.emu_start(0xA7194, MOCK_RET)
ciphertext = bytes(mu.mem_read(PT_ADDR, 16))关键注意: sub_A7194 会修改 ctx 缓冲区,每次加密前必须恢复 saved_ctx。
状态缓冲区写入追踪:
def hook_mem_write(uc, access, addr, size, value, data):
if PT <= addr < PT + 16:
pc = uc.reg_read(UC_ARM64_REG_PC)
offset = addr - PT
write_log.append((classify_pc(pc), offset, value & 0xFF))通过将写入按 PC 地址范围分类,识别出以下操作:
| PC 范围 | 操作名 | 说明 |
|---|---|---|
| 0xaaad0-0xaaae0 | INIT1 | 初始 XOR (第一组) |
| 0xa7ae0-0xa7b00 | INIT2 | 初始 XOR (第二组) |
| 0xaad10-0xaad30 | ARK | AddRoundKey |
| 0xa8420-0xa8430 | SB | SubBytes (列优先写入顺序) |
| 0xa92d0-0xa92e0 | PERM | 字节置换 + 密钥XOR |
| 0xaadf0-0xaae50 | SR | ShiftRows (部分) |
| 0xa7050-0xa7160 | MC | MixColumns (含 gf_mul 调用) |
| 0xa8640-0xa8660 | FINAL | 最终轮 XOR |
进一步分析内存里面的操作序列,对 PT=0x30*16 加密产生 58 次写入组,对应以下结构:
INIT1 → INIT2 → ARK # 初始化 (3步)
[SB → PERM → SR → MC → ARK] × 10 # 中间轮 (50步)
SB → PERM → SR → ARK → FINAL # 最终轮 (5步)加密总计 11 轮: 10 个完整轮 + 1 个无 MixColumns 的最终轮。悲催的是!CFF 混淆将标准的 ShiftRows 拆分成了两个独立的操作:
- PERM (PC ≈ 0xa92dc): 固定字节置换 + 密钥异或
- SR (PC ≈ 0xaadf8): 另一组字节置换
通过恒等 S-box 差分分析确认: PERM 置换 + SR 置换 = 已知的 ShiftRows 置换:
PERM: [3,7,11,15,2,6,10,14,1,5,9,13,0,4,8,12]
SR: [0,5,14,11,4,9,2,15,8,13,6,3,12,1,10,7]
组合: output[i] = input[[12,11,5,2,13,8,6,3,14,9,7,0,15,10,4,1][i]]PERM 操作的隐含密钥: PERM 不仅做置换,还对每个字节异或一个按轮变化的常量。这个密钥被 CFF 隐藏在分发逻辑中,无法通过纯静态分析提取。
2.4.5.3 轮函数逐步还原
先进行SubBytes 验证,比较 ARK 输出(SB 输入)与 SB 输出,逐字节检查 SBOX[input[i]] == output[i]。
# 对多组测试向量验证
for i in range(16):
assert SBOX[state_before_sb[i]] == state_after_sb[i]
# 结果: 全部 PASS轻易分析得出 SubBytes 就是标准的 S-box 字节替换,无额外操作。
ShiftRows 置换的提取,选择用恒等 S-box 做差分分析。将 S-box 替换为 sbox[i]=i,使 SubBytes 变为恒等操作。然后设置一个字节为 1、其余为 0,追踪差异位置如何在 PERM→SR 组合操作中移动。
输入差异在 byte 0 → 组合后差异在 byte 11
输入差异在 byte 1 → 组合后差异在 byte 15
输入差异在 byte 2 → 组合后差异在 byte 3
...最终得到置换表 (output[i] = input[perm[i]]):
SR_PERM[16] = {12, 11, 5, 2, 13, 8, 6, 3, 14, 9, 7, 0, 15, 10, 4, 1};还需要确认MixColumns 系数,先去ida静态分析尝试,在 PC=0xa7058 附近的代码中,可以看到 BLR X19 调用 gf_mul (sub_A96F0),并且参数中出现常量 6, 3, 5, 2:
a7064 MOV W0, W22
a7068 MOV W1, #6 ; coefficient = 6
a706c BLR X19 ; gf_mul(state_byte, 6)
...
a7078 MOV W1, #3 ; coefficient = 3
...
a7088 MOV W1, #5 ; coefficient = 5
...接下来组差分验证对多个测试向量的 SR→MC 转换做差分分析,确认每个输出字节依赖恰好 4 个输入字节,且依赖系数构成 [6,3,5,2] 的循环矩阵:
MixColumns 矩阵 (GF(2^8)/0x171):
┌ ┐
│ 6 3 5 2 │
│ 2 6 3 5 │
│ 5 2 6 3 │
│ 3 5 2 6 │
└ ┘
对4组连续字节 [0-3], [4-7], [8-11], [12-15] 分别应用GF(2^8) 有限域分析略过,不可约多项式实际为: 0x171 = x^8 + x^6 + x^5 + x^4 + 1 (不同于标准 AES 使用的 0x11b = x^8 + x^4 + x^3 + x + 1)
uint8_t gf_mul(uint8_t a_in, uint8_t b) {
uint16_t p = 0, a = a_in; // 注意: a 必须用 uint16_t
for (int i = 0; i < 8; i++) {
if (b & 1) p ^= a;
b >>= 1;
a <<= 1;
if (a & 0x100) a ^= 0x171; // 模约化
}
return (uint8_t)p;
}AddRoundKey 验证一下,主要是对两个不同明文,计算 MC_output XOR ARK_output,检查是否得到相同的密钥。
k0 = MC_output_test0 XOR ARK_output_test0 # 测试 0
k1 = MC_output_test1 XOR ARK_output_test1 # 测试 1
assert k0 == k1 # 校验对比: 纯 XOR 操作 (fuqiuluo)有效轮密钥提取:
CFF 混淆将 ShiftRows 拆分为 PERM + SR 两步,且 PERM 步骤在置换的同时异或了一个按轮变化的密钥。这个密钥无法通过纯静态分析提取。如果忽略 PERM 密钥,直接使用 SB → 组合SR → MC → ARK 结构和 ctx 中的标准轮密钥,加密结果完全错误。
由Claude和Gemini 3.1 Pro交流我们得到:PERM 密钥 K_perm 在 MC 之前,而 MC 是线性的!材料全丢给AI,分析过程如下:
MC(SR(permute(SB(state)) ⊕ K_perm))
= MC(SR(permute(SB(state)))) ⊕ MC(SR(K_perm))
= MC(combined_SR(SB(state))) ⊕ MC(SR(K_perm))因此可以定义 有效轮密钥:
eff_key[r] = MC(SR(K_perm_r)) ⊕ ARK_r这样轮函数简化为标准形式:
state = MC(combined_SR(SB(state))) ⊕ eff_key[r]利用 Unicorn 追踪得到每轮 ARK 前后的状态:
for r in range(1, 11):
prev_state = ark_states[r-1] # 上一轮 ARK 输出 = 本轮 SB 输入
after_ark = ark_states[r] # 本轮 ARK 输出
# 用纯 Python 计算 SB → SR → MC
sb_out = SubBytes(prev_state)
sr_out = ShiftRows(sb_out) # 使用组合置换
mc_out = MixColumns(sr_out)
# 有效密钥 = MC 输出 ⊕ ARK 输出
eff_key[r] = mc_out ⊕ after_ark验证: 对两组不同明文分别提取,10 个有效轮密钥完全一致,确认提取正确。
最终轮无 MixColumns:
last_ark = ark_states[10] # 倒数第二个 ARK (= 最终轮 SB 输入)
ciphertext = final_output
final_key = ShiftRows(SubBytes(last_ark)) ⊕ ciphertext注意: 必须使用倒数第二个 ARK 状态 (ark_states[-2]),不是最后一个。因为最后一个 ARK 状态 (ark_states[-1]) 是最终轮内部的中间状态,不是 SB 的输入。
恒等 S-box 分析的陷阱:
将 S-box 替换为恒等映射
sbox[i]=i后,密钥调度sub_A7DE8也使用了该 S-box,导致轮密钥完全不同。因此恒等 S-box 下的分析不能直接与真实 S-box 下的结果混用——只能用于提取线性结构(置换、扩散矩阵),不能用于提取密钥。gf_inv 的循环次数分析错误:
// 错误: 循环 253 次 → 计算 a^253 for (int i = 0; i < 253; i++) r = gf_mul(r, a); // 正确: 循环 254 次 → 计算 a^254 = a^(-1) (阶为 255) for (int i = 0; i < 254; i++) r = gf_mul(r, a);逆 MixColumns 矩阵的时候全部算错,解密完全失败。正向加密不受影响。
8.5 工具清单
| 文件 | 功能 |
|---|---|
part2/part2_final.c | 最终纯C实现 (加密+解密, 已验证) |
part2/part2_solve.py | Unicorn 模拟器求解器 (验证用) |
part2/trace_correct.py | 按操作分组的状态追踪 |
part2/extract_effective_keys.py | 有效轮密钥提取与验证 |
part2/trace_ops.py | 恒等S-box差分分析 |
part2/trace_ops2.py | 全尺寸写入追踪 |
part2/debug_algo.py | 单步对比调试 |
part2/emu_analyze.py | Unicorn 分析框架 |
tool/bypass_libsec2026.js | 反调试绕过 (仅改RW段) |
part2/trigger_part2.js | 触发 Part2 碰撞 |
part2/dump_keyschedule_direct.js | 直接调用 sub_A7900 提取密钥 |
9 Part3 分析
9.1 题目特点
Part3 相比前两部分明显更偏原生层与混淆执行。根据调用栈与原生分析结果,可以定位到 flag{sec2026_PART3_<L><R>} 的格式化输出点,并确认最终 flag 来自一个多层混淆保护下的自定义计算过程。
分析根据之前对碰撞的分析结果,方块不仅隐形还没有碰撞,我们先恢复碰撞,传送到方块旁边,无方块显形截图:
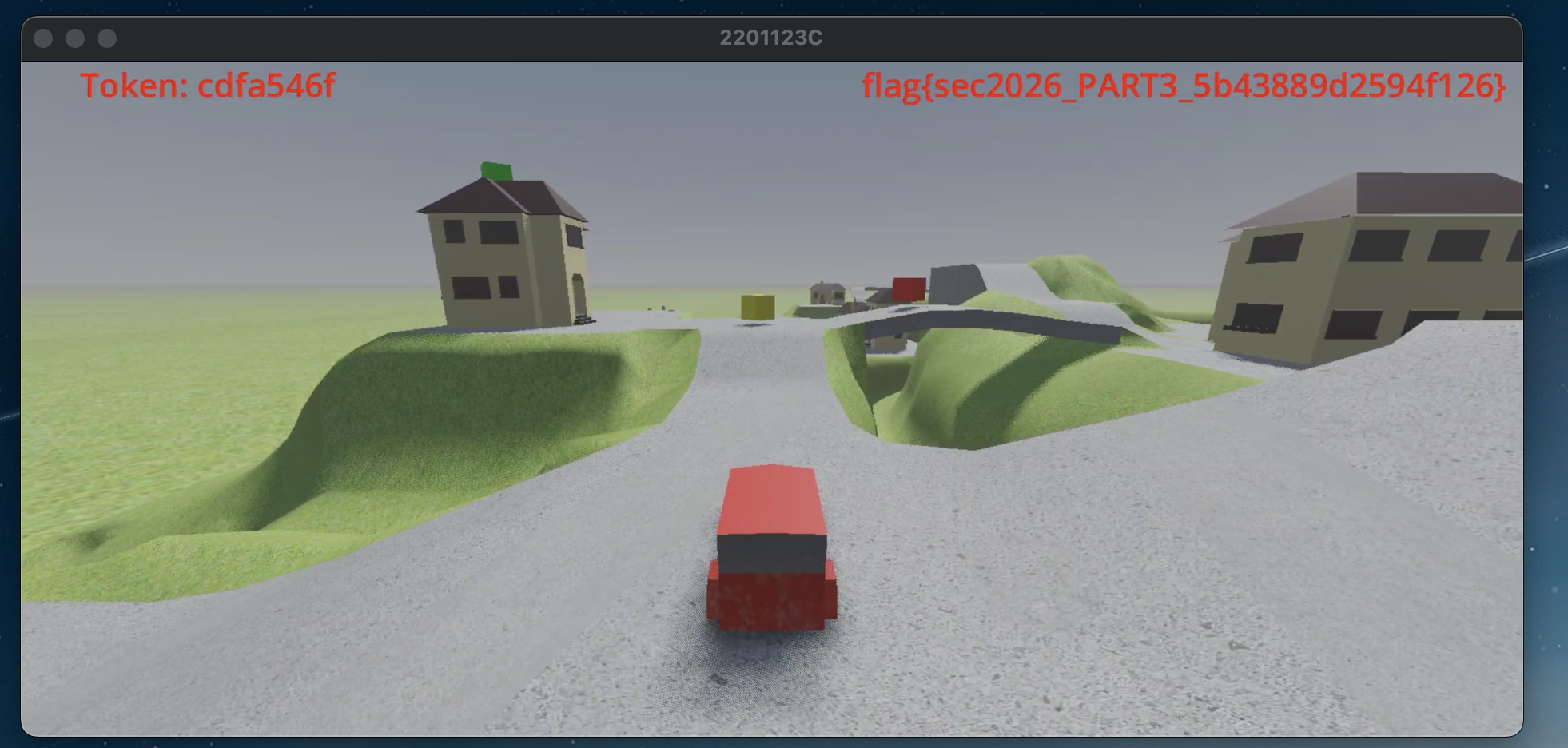
- MeshInstance3D: BoxMesh,visible=true, scale=(1,1,1)
- 材质: transparency 设为 0(不透明)
- 碰撞: CollisionShape3D 启用
- 位置: (3.75, 4.59, -16.56)

9.2 Flag 生成定位
🤔GodotScript层没有发现任何PART3到痕迹,有两个思路可以选,选择全部移交VM实现(例如纯vm到libc)或者提供一个vm到handler直接使用libc的vsprintf,通过对 memcpy 与 vsprintf 一类函数下 hook,这里hit到了所以说很显然是后者,结合调用栈回溯:
=== CALL STACK ===
#0 libsec2026.so+0xaa734 (0x79d62f7734)
#1 libsec2026.so+0xaa734 (0x79d62f7734)
#2 libsec2026.so+0xaa88c (0x79d62f788c)
#3 libsec2026.so+0x1383b8 (0x79d63853b8)
#4 libsec2026.so+0x1383b8 (0x79d63853b8)
=== END STACK ===经过AI静态分析做的函数的重命名我们可以了解到aa88c是vm4_entry_handler ,也就是vspintf到地方,结合其他地方的调用栈分析可以得到以下信息,定位到:
- 外层状态机入口。
- VM4 / VM2 / VM3 多层解释执行结构。
- 最终格式串 "%08x%08x" 的拼接点。
最后可将输出过程概括为:
- 对输入 token 做两次 VM 计算,分别得到 L 与 R。
- 使用格式串输出为 8 位十六进制拼接。
- 组合成
flag{sec2026_PART3_<L><R>}。
9.3 为什么引入 Unicorn
Part3 的难点不在于定位输入输出点,而在于中间计算过程被四层结构同时保护:
- SBC0 字节码层(VMP)。
- 外层 CFF 状态机。
- 内层 CFF 状态机。
- ARM64 原生指令层。
静态分析会陷入海量间接跳转与状态跳转,效率极低。为此构建了 Unicorn 模拟环境,将其作为分析 oracle,而不是最终求解载体。进行一次简单的trace分析我们可以得到:
| 偏移 | 名称 | 说明 |
|---|---|---|
0xA9A7C | sub_A9A7C | 外层状态机入口 |
0xAA758 | vm4_entry | VM4 入口(调 vm2 两次) |
0xAA6AC | vsprintf_wrapper | 最终格式化输出点 |
0xAA0CC | memcpy_token1 | 复制 token 到 0x1836C0 |
0xAA0F0 | memcpy_token2 | 复制 token 到 0x1836C8 |
0x1385BC | vm2_entry | VM2 入口(12 opcodes) |
0x13879C | vm3_entry | VM3 入口(12 opcodes) |
0x63D88 | SBC0_header | SBC0 字节码数据(header + 8192 bytes) |
0x1836C0 | input_buffer | 输入缓冲区(token×2) |
0x1836E0 | output_buffer | 输出缓冲区(flag hex) |
0x183920 | fmt_string | 格式串 "%08x%08x"(运行时 XOR 解密) |
9.4 混淆结构识别
使用 Unicorn 的范围化 Hook 替代全局 per-instruction Hook:
# 慢(34M 指令全 hook): ~30-60s
mu.hook_add(UC_HOOK_CODE, handler)
# 快(仅 hook PLT + 停止点): ~0.7s
mu.hook_add(UC_HOOK_CODE, plt_handler, begin=0x300000000, end=0x300010000)
mu.hook_add(UC_HOOK_CODE, stop_handler, begin=0xAA6AC, end=0xAA6B0)0.7s/次的 oracle 速度使大规模差分分析成为可能。
Layer 1: SBC0 字节码 (0x63D88)
├── 8192 字节虚拟指令, 9 种操作码 (0x00-0x09)
└── 由 Layer 2 解释执行
Layer 2: 外层 CFF 状态机 (0x13D5B4)
├── 调度表: 0x180E80 (state → index)
├── 跳转表: 0x180658 (index → handler)
├── 11 个活跃状态, 87 个 handler 函数
└── 循环: 73→6→0→50→29→10→68→23→31→79→53
Layer 3: 内层 CFF 状态机 (0x13DE90)
├── 调度表: 0x1813A0
├── 跳转表: 0x180FE0
├── 34 个活跃 handler
└── 每条字节码指令触发 45-66 次内层转换
Layer 4: ARM64 原生指令
└── 44 种指令编码类, 3400 万条指令总执行量在模拟与跟踪后,识别出:
- AI辅助分析得到 SBC0 共使用多类字节码操作。
| 操作码 | 处理器状态 | Handler 地址 | 功能 | 出现次数 |
|---|---|---|---|---|
| 0 | 68 (默认) | 0x13D810 | 加载/取字段值 | 8180 |
| 1 | 12 | 0x13DD30 | XOR 解码 (0xA5A5/0x5A) | 2348 |
| 2 | 17 | 0x13E600 | 比较/条件分支 | 1282 |
| 3 | 81 | 0x13E094 | SUB 0x1337/XOR 0xCC 解码 | 6800 |
| 4 | 68 (默认) | 0x13D810 | 算术运算 | 6948 |
| 5 | 85 | 0x13E254 | MADD 变换 (0x53/0x2B/0x6D/0x72) | 112 |
| 6 | 68 (默认) | 0x13D810 | 移位操作 | 4982 |
| 7 | - | - | 跳转/分支 | 116 |
| 9 | 68 (默认) | 0x13D810 | 复杂调用 | 1068 |
- 每条 SBC0 字节码触发 45-66 次内层 CFF 状态转换,总计 84.8 万次。
- 存在明显的多轮迭代结构。
- 轮间状态通过某些固定寄存/缓冲位置传递。
9.5 黑盒与差分分析结果
利用 0.7s/次的快速 Unicorn Oracle,系统性收集了以下数据:
- 19 组设备 oracle 对 — 从 Frida 在真机上触发收集
- 256 组 byte[0] 扫描 — byte[0]=0x00..0xFF,其余=0x00
- 16 组 ASCII 位置扫描 — 每个位置 '0'-'f' 遍历
通过大量 oracle 数据采集与差分比较,可以确认:
- 算法不是简单线性 XOR/ADD 型变换。
- 存在明显雪崩效应。
- 输入字节之间并非独立。
- 并不匹配常见标准算法,如 TEA/XTEA/SipHash/FNV 等。
9.5.1 堆内存写入追踪
在 Unicorn 中 hook 所有 memcpy 调用,追踪对堆结果区域 0x40032E700 的写入:
# 当 memcpy 目标落在结果区域时记录
if d2 == RESULT_BASE + 0x98 and n == 8:
counter = struct.unpack('<I', dd[:4])[0]
vals = [read_uint32(RESULT_BASE + off) for off in range(0x10, 0x90, 8)]
round_data.append((counter, vals))追踪发现结果区域有 29 轮写入(计数器 1→29),每轮写入 16 个 uint32 值(v[0]→v[15])加上保存值和计数器:
Round 0 (init): v[0]=L_in, v[1..15]=0
Round 1 (cnt=2): v[0]=0x03030300, v[1]=0xFC60694A, ..., v[15]=0x522BDB51
Round 2 (cnt=3): v[0]=0x22BDB510, v[1]=0x1C1B1B5A, ..., v[15]=0x5531A5D7
...
Round 28(cnt=29): v[0]=0x50403970, ..., v[7]=0x66D6A4FA(=R), v[15]=0xB45B42CB(=L)9.5.2 轮间转换: v[15] << 4:
Round N 的 v[15] << 4 = Round N+1 的 v[0]
验证:
Round 1 v[15] = 0x522BDB51, <<4 = 0x22BDB510 = Round 2 v[0] ✓
Round 2 v[15] = 0x5531A5D7, <<4 = 0x531A5D70 = Round 3 v[0] ✓
Round 27 v[15] = 0xF5040397, <<4 = 0x50403970 = Round 28 v[0] ✓9.5.3 多输入差分比较
对 9 组不同输入(00000000, 10000000, 01000000, ..., 00000001)分别运行 oracle,提取每轮 16 个值,逐位对比。
9.5.3.1 固定关系发现
通过差分确认 4 个固定加法常量:
v[1] = v[0] + 0xF95D664A (C0) — 全部 29 轮, 全部输入一致 ✓
v[5] = v[4] + 0x12AA364C (C1) ✓
v[9] = v[8] + 0x33AD3CEE (C2) ✓
v[13] = v[12] + 0xAABBCCDD (C3) v[3] = v[1] ^ v[2] ✓
v[11] = v[9] ^ v[10] ✓XOR 关系:
v[3] = v[1] ^ v[2] ✓
v[11] = v[9] ^ v[10] ✓9.5.3.2 递推关系发现
v[7]_round_n - v[6]_round_n = v[7]_round_{n-1} ✓ (全部 28 轮)
v[15]_round_n - v[14]_round_n = v[15]_round_{n-1} ✓
即:
v[7] = v[6] + v7_accumulator (累加器)
v[15] = v[14] + v15_accumulator (累加器)9.5.3.3 VM 上下文槽位分析
追踪 7 个 VM 上下文槽位(堆地址 0x4003376D8-0x400337708),发现:
slot[0] = K × 0x29E59C9F ← 等差数列! 轮常量 RC, 不依赖输入!
slot[1] = R_in ← token 后 4 字节
slot[2] = (K-1) × 0x29E59C9F ← 前一轮的 RC
slot[3..6] = 常量 (0, 1, 0x17008, 0)验证:
Round 1: slot[0] = 0x29E59C9F = 1 × 0x29E59C9F ✓
Round 2: slot[0] = 0x53CB393E = 2 × 0x29E59C9F ✓
Round 3: slot[0] = 0x7DB0D5DD = 3 × 0x29E59C9F ✓
差值恒为 0x29E59C9F ✓9.5.3.4 v[2] 和 v[4] 公式推导
有了轮常量 RC = K × 0x29E59C9F,验证:
# v[2] = RC + state (state = prev_v15 = 累加器)
v2_predicted = (RC + prev_v15) & 0xFFFFFFFF
# 全部 28 轮 × 4 种输入 = 112 次验证, 全部通过 ✓
# v[4] = state >> 7
v4_predicted = prev_v15 >> 7
# 全部通过 ✓9.5.3.5 第二阶段公式推导
发现 v[8], v[10], v[12] 均由同一轮的 v[7] 派生:
v[8] = v[7] << 6 # 左移 6 位 ✓
v[10] = RC + v[7] # 与 v[2] 相同结构! ✓
v[12] = v[7] >> 5 # 右移 5 位 ✓验证(Round 1, token "00000000"):
v[7] = 0xE5AF6359
v[8] = 0xE5AF6359 << 6 = 0x6BD8D640 ✓ (截断 32 位)
v[10] = 0x29E59C9F + 0xE5AF6359 = 0x0F94FFF8 ✓
v[12] = 0xE5AF6359 >> 5 = 0x072D7B1A ✓9.5.3.6 v[6] 和 v[14] 推导
由 XOR 和递推关系:
v[6] = v[3] ^ v[5] ✓ (已知 v[3]=v[1]^v[2], v[5]=v[4]+C1)
v[14] = v[11] ^ v[13] ✓ (已知 v[11]=v[9]^v[10], v[13]=v[12]+C3)至此,16 个值全部由 v[0](即 state<<4)、RC、v7_acc、v15_acc 确定。算法完全闭合。
9.6 算法还原
经过密码学的攻击比较,我们可以得到完整的流程为:
输入: 8 字节 ASCII hex token (如 "fd092380")
拆分: L_in = token[0:4] 作为 uint32 LE = 0x39306466
R_in = token[4:8] 作为 uint32 LE = 0x30383332
state = R_in
v7_acc = L_in
v15_acc = R_in
for K = 1 to 28:
RC = K × 0x29E59C9F // 轮常量 (mod 2^32)
v0 = state << 4 // 左移 4 位
v1 = v0 + 0xF95D664A // 加常量 C0
v2 = RC + state // 轮常量 + 状态
v3 = v1 ⊕ v2 // XOR
v4 = state >> 7 // 右移 7 位
v5 = v4 + 0x12AA364C // 加常量 C1
v6 = v3 ⊕ v5 // XOR
v7 = v6 + v7_acc // 累加
v8 = v7 << 6 // 左移 6 位
v9 = v8 + 0x33AD3CEE // 加常量 C2
v10 = RC + v7 // 轮常量 + v7
v11 = v9 ⊕ v10 // XOR
v12 = v7 >> 5 // 右移 5 位
v13 = v12 + 0xAABBCCDD // 加常量 C3
v14 = v11 ⊕ v13 // XOR
v15 = v14 + v15_acc // 累加
// 更新累加器
v7_acc = v7
v15_acc = v15
state = v1
L = v15_acc // vsprintf 的 X3 参数
R = v7_acc // vsprintf 的 X4 参数
flag = "flag{sec2026_PART3_" + hex(L, 8) + hex(R, 8) + "}"这是一个双阶段 Feistel-like (XTEA) 累加密码:
- 第一阶段:
v7 = F1(state, RC) + v7_acc,其中 F1 使用移位(<<4, >>7)、加法(C0, C1)、XOR
- 第二阶段:
v15 = F2(v7, RC) + v15_acc,结构完全对称,使用移位(<<6, >>5)、加法(C2, C3)、XOR
- 轮常量 RC = K × 0x29E59C9F(线性递增)
- 28 轮后 v7_acc 和 v15_acc 分别输出为 R 和 L
9.7 工具清单
| 文件 | 功能 |
|---|---|
part3/part3_final.c | 最终纯C实现 (28 轮加密, 19 组验证通过) |
part3/emu_part3.py | Unicorn 模拟器 oracle (基础版) |
part3/part3_fast_oracle.py | 快速 oracle (0.7s/次, 范围化 Hook) |
part3/part3_trace_memcpy.py | memcpy 追踪 (数据流分析) |
part3/part3_round_func.py | 29 轮数据完整捕获 |
part3/part3_structure.py | 多输入差分分析 (中间值比较) |
part3/part3_extract_algo.py | 中间值提取与关系验证 |
part3/part3_trace_cff.py | CFF 状态机追踪 (11 态循环) |
part3/part3_vm_decode.py | SBC0 字节码执行追踪 |
part3/part3_analyze.py | 黑盒算法分析 |
part3/part3_match_algo.py | 已知算法匹配测试 |
part3/part3_result_trace.py | 堆结果区域监控 |
part3/part3_field_trace.py | VM 字段值追踪 |
part3/part3_decode_sbc0.py | SBC0 指令流解码 |
part3/part3_trace_part3.py | 算术指令追踪 |
part3/part3_trace_part3_discover.py | 代码路径发现 |
part3/oracle_data.py | 35 组 oracle 数据集 |
part3/oracle_part3.js | Frida 真机 oracle 收集 |
part3/stalker_part3.js | Stalker 执行路径追踪 |
part3/probe_part3.js | Frida 场景探测 |
part3/trigger_part3.js | 碰撞触发脚本 |